
视觉BEV综述
感知BEV综述
什么是BEV
BEV的意思是鸟瞰图,也就是我们会将环视摄像机,激光雷达,甚至是毫米波雷达的数据,经过特征提取之后,统统通过视角变换,转换到鸟瞰图这种场景下,然后会在这些场景下,做一些多传感器数据融合就很方便了,之后我们就可以接各种任务头,做3D目标检测,车道线检测,语义分割,障碍物检测等等,都是可以的。
对于低成本的自动驾驶系统,以视觉为中心的BEV感知是一个长期的挑战,因为摄像头通常放置在自车上,与地面平行,面向外部。图像在与BEV正交的透视图(PV)中获取,并且两个视图之间的变换是不适定问题。最早工作[用单应矩阵以物理和数学方式将平坦地面从PV转换为BEV。多年来,这种方法一直占据主导地位,直到平地硬约束无法满足复杂真实场景的自主驾驶要求。随着计算机视觉中数据驱动方法的发展,近年来出现了许多基于深度学习的方法,通过求解PV-BEV变换来促进以视觉为中心的BEV感知。
BEV方法
基于视图变换,当前BEV视觉感知工作可分为两大类:基于几何的变换和基于网络的变换。如图1所示:
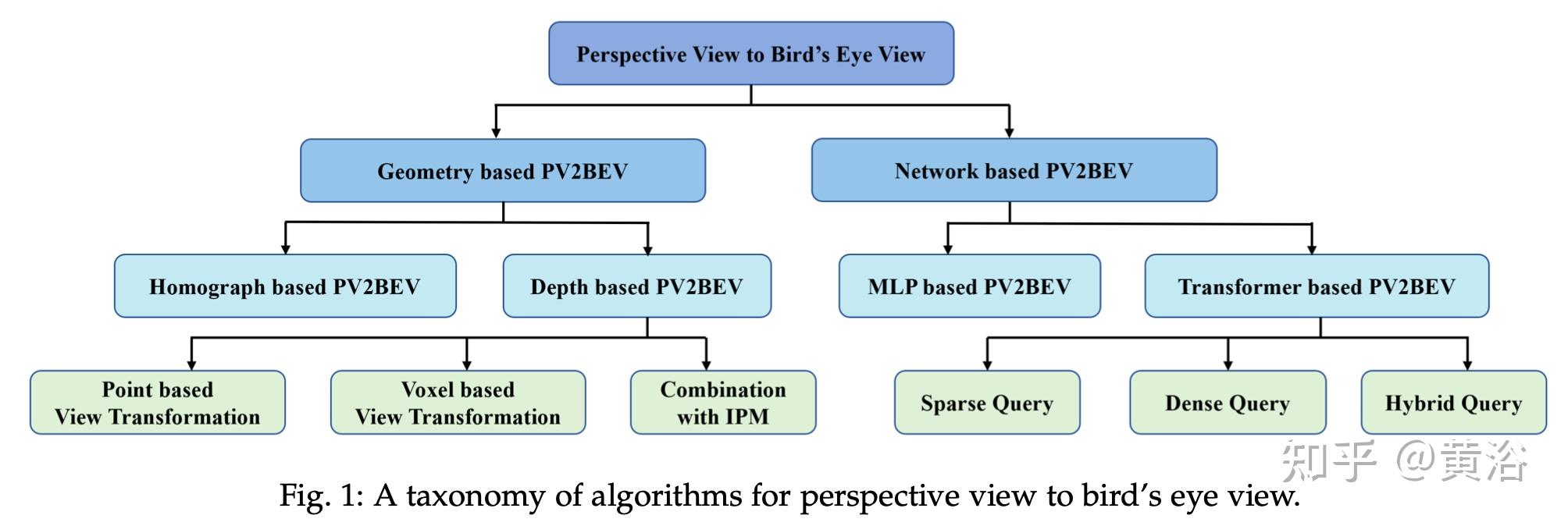
前者充分利用摄像头的物理原理以可解释的方式迁移视图。除了经典的基于homograph的方法外,通过显式或隐式深度估计将2-D特征提升到3-D空间是主要的解决方案。对于图像的每个像素,都存在一条来自摄影机的光线,该光线会遇到现实世界中的目标。不直接将像素映射到BEV,另一种方法是计算每个像素的深度分布,利用该分布将2D特征提升到3D,然后通过降维从3D获得BEV表示。
这些方法对深度采用不同的假设,例如精确值、射线上的均匀分布或射线上的类分布。深度监督来自于最终的显示深度值或任务监督。对于后者,其方法采用神经网络作为PV到BEV的视图投影。深度神经网络充当一个负责的映射函数,以不同的模式、维度、表示等将输入转换为输出。简单的想法是使用编码器-解码器(VE-D)或MLP将PV特征投影到BEV。上述方法在某种程度上采用了自下而上(bottom-up)的策略,以前向的凡是处理转换。另一种方法是采用自顶向下(top-down)的策略,通过交叉注意力机制直接构造BEV query并搜索前视图像上的相应特征。为了匹配不同的下游任务,各种方法提出稀疏、密集或混合query。
3-D目标检测是3-D感知的核心任务之一。根据不同的输入数据模式,该任务可以分为:基于图像、基于激光雷达和基于多模态的3-D检测。
基于图像的3D检测设置需要模型预测仅给定多个图像的目标类别和3-D边框。以前的工作通常直接从透视图特征进行预测,这个过程虽然简单,但在实践中对多视图摄像头数据进行复杂的后处理,难以利用来自多个视图和时间连续帧的立体视觉线索。因此,最近基于BEV的方法进入视野。
将透视图转化为BEV的一个传统而直接的解决方案是,利用二者之间的自然集合投影关系,称之为几何方法。根据如何弥合这两个视图间的差距,以前的工作可分为两组:基于homograpgh的方法和基于深度的方法。
基于homograph的方法
3-D空间中的点可以通过透视映射变换到图像空间,而将图像像素投影到3-D空间的逆问题是病态的。逆透视映射(IPM),基于逆映射点位于水平面的夫君爱约束,解决数学上不可能的映射问题。单应矩阵可以从相机的内外参物理地导出。一些方法用CNN提取PV图形的语义特征,并估计图像中的垂直消失点和地平面消失线,以确定单应矩阵。
由于IPM严重依赖于平坦地面假设,这些给予IPM的方法通常无法准确检测地平面上方的目标,如建筑物、车辆和行人。
总结:基于homograph方法主要基于PV和BEV之间平地面的物理映射,具有良好的可解释性。IPM在下游感知任务的图像投影或特征投影中起作用。为了减少地平面以上区域的失真,充分探索语义信息,并广泛使用GAN来提高BEV特征的质量。由于从PV到BEV的实际转换是不适定的,IPM的硬假设解决来部分问题。PV整个特征图的有效BEV映射仍有待解决。
基于深度预测的方法
基于深度的PV-BEV方法自然建立在显示3D表示上。基于所使用的表示,这些方法可以分为两种类型:基于点的方法和基于体素的方法。
- 基于点的视图转换
基于点的方法直接使用深度估计将像素转换为点云,在连续3-D空间中散播。其更直接,更容易集成单目深度估计和基于激光雷达的3D检测成熟经验。
- 基于体素的视图变换
与基于激光雷达的3-D检测方法类似,纯摄像头方法也有两种常见的选择来表示变换后的3-D特征和几何。与分布在连续3-D空间中的点云相比,体素通过离散3-D空间来构造用于特征变换的均匀结构,为3-D场景理解提供来更有效的表示。
具体而言,该方案通常使用深度引导直接在相应位置的3D位置散射2D特征(而不是点)。先前的工作将2D特征图与相应的预测深度分布进行外积(outer product)来实现这一目标。早期的工作假设分布是均匀的,即沿射线的所有特征都相同,如OFT。这项工作建立了一个内部表示,以确定图像中哪些特征与正交BEV上的位置相关。在定义的均匀间隔3-D格上,它构建3-D体素特征图,并在投影的相应图像特征图区域累积特征来填充体素。然后,沿垂直轴对体素特征求和获得正交特征图,然后深度卷积神经网络提取BEV特征用于3-D目标检测。对于图像的每个像素,网络对分配的3D点预测相同的表示,即预测沿深度的均匀表示。这类方法通常不需要深度监督,并且可以在视图转换之后以端到端方式学习网络中的深度或3D位置信息。
相反,另一种范式会明确预测深度分布,并以此仔细构建3D特征,LSS代表了这种方法。其预测深度上的类分布(categorical distribution)和上下文向量,其外积确定透视光线每个点的特征,更好地接近真实深度分布。此外,它将来自所有摄像头的预测融合到场景的一个结合表征中,对标定误差更有鲁棒性。BEVDet遵循这一LSS范式,提出了一种从BEV进行全摄像头多视图的3D检测框架。而新版本BEVDet4D展示了基于多摄像头3D检测的时域线索。具体而言,保留前一帧的中间BEV特征,并将其与前帧生产的特征连接。
- 深度监督
当使用预测深度分布来提升2-D特征时,该分布精度非常重要。CaDDN用经典方法对激光雷达点投影的稀疏深度图进行插值,并以此监督深度分布的预测。其他不用深度标签的方法,只能从稀疏实例标注中学习此类3D位置或深度信息,仅靠网络学习,要困难得多。除了将深度监督纳入检测框架之外,DD3D和MV-FCOS3D++指出,深度估计和单目3D检测的预训练可以显著增强2D主干的表征学习。
- 与基于IPM的方法相结合
PanopticSeg利用这两个方法的优点,提出一种用于全景分割的dense transformer模块,其包括一个用IPM的flat transformer,然后误差校正,生成平面BEV特征,还有一个用3-D体格(volumetri lattice)建模中间3D空间的vertical transformer。
- 多视图聚合做立体匹配
除了单目深度估计外,立体匹配还可以在纯摄像头感知中预测更精确的深度信息。它依赖于适当多视图设置自然形成的基线。相比之下,在双目情况下的深度估计中具有更重要的优点。
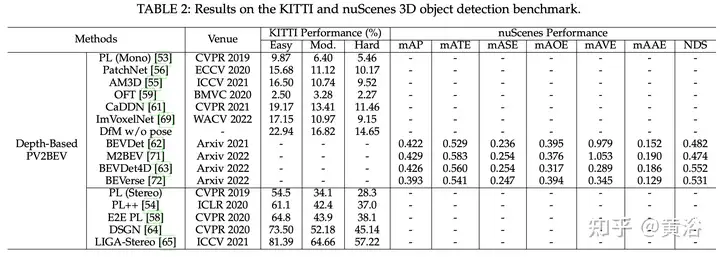
基于深度的视图变换方法通常基于显式3-D表示、量化体素或连续3-D空间的点云散射。基于体素的方法使用均匀的深度向量或明确预测的深度分布将2D特征提升到3D体素空间,并执行几乎BEV的感知。相反,基于点的方法将深度预测转化为伪激光雷达表示,然后用定义网络进行3-D检测。如下表显式了3-D检测的结果:
下图是基于深度的方法时间顺序概述:
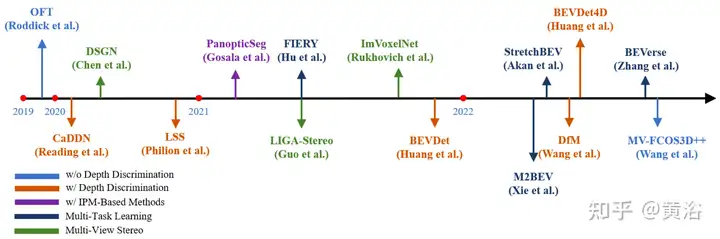
总而言之:
1.早期的方法通常第一步用伪激光雷达表示,在第二步直接用3D检测器;然而,由于难以进行可推广的端到端训练,而面临着模型复杂度和性能低的问题。
2.由于计算效率和灵活性,最近的方法更加关注基于体素的方法。这种表示已广泛应用于不同任务的纯摄像头方法中。
3.深度监督对于这种基于深度的方法很重要,因为准确的深度分布可以为特征PV转换为BEV时提供基本线索。
4.如DfM、BEVDet4D和MV-FCOS3D++所分析的,在时域建模中此类方法是一个有希望的方向。
基于几何的方法明确建立在摄像头投影过程的物理原理上,将视图pV转换为BEV,这是一种可解释的解决方案。另一种选择是以数据驱动的方式对视图进行建模,有效地利用摄像头几何结构,其中神经网络充当PV和BEV之间的映射函数。为了涵盖单应性等复杂变幻,MLP和transformer是基于网络方法的两个合适选择。
基于MLP的视图转换
多层感知器(MLP)在某种程度上可以看为一个复杂的映射函数,其将输入映射到具有不同模态、维度或表示的输出。摆脱标定摄像机设置包含的继承感应偏差,一些方法倾向于利用MLP学习摄像机标定的隐式表示,实现在两个不同视图(PV和BEV)之间转换。
基于MLP的方法忽略了标定摄像机的几何先验,并利用MLP作为通用映射函数来建模从PV到BEV的转换。虽然MLP在理论上是一种通用的近似器,但由于缺乏深度信息、遮挡等原因,这使得基于MLP的方法无法利用重叠区域带来的几何潜力。
总之,基于MLP的方法更多地关注单个图像的情况,而多视图融合还没有得到充分的研究。
基于Transformer的视图转换
Transformer解决方案,无需明确利用摄像头模型。基于MLP和基于Transformer的张量映射之间有三个主要区别:
1)由于加权矩阵在推理过程中是固定的,因此MLP学习的映射不依赖于数据,相反,Transformer中的交叉注意与数据相关,其中加权矩阵与输入数据相关。此数据相关属性使Transformer更有表现力。
2)交叉注意是置换不变的,需要位置编码来区分输入顺序;MLP对排列自然敏感。
3)基于Transformer的方法采用自顶向下的策略,通过构造query并通过注意机制搜索相应的图像特征,而不是像基于MLP的方法那样以前向方式处理视图变换。
根据Transformer解码器中可学习slots(称为query)的粒度,将这些方法分为三类:基于稀疏query的方法、基于密集query的方法和基于混合query的方法。
基于稀疏query的方法
对于基于稀疏查询的方法,查询嵌入使网络能够直接产生稀疏感知结果,而无需显式执行图像特征的密集变换。
DETR3D侧重与多摄像机输入的3D检测,并用基于几何的特征采样过程代替交叉注意。它首先从可学习的稀疏查询中预测3-D参考点,然后使用标定矩阵将参考点投影到图像平面上,最后对相应的多视图多尺度图像特征进行采样,进行端到端的3-D边框预测。为了缓解DETR3D中复杂的特征采样过程,PETR将摄像机参数导出的3-D位置嵌入编码到2-D多视图特征中,这样稀疏查询可以直接与交叉注意中位置-觉察图像特征进行交互,实现更简单、更优雅的框架。下图为PETR3D与PETR比较:
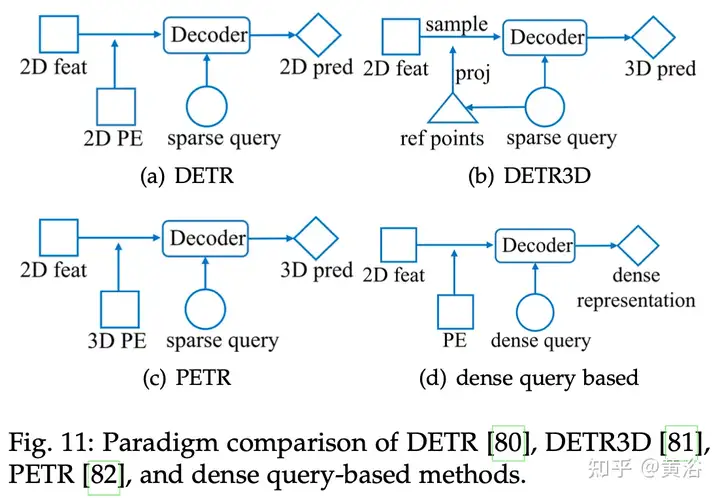
PETRv2将3D位置嵌入扩展到时域来利用时域信息。
基于密集query的方法
对于基于密集查询的方法,每个查询都预先分配3D空间或BEV空间的空间位置。查询数目有光栅化空间的空间分辨率决定,通常大于基于稀疏查询的方法。密集BEV表示可以密集查询与多个下游任务图像特征之间的交互来实现。
基于混合query的方法
基于稀疏查询的方法适用于以目标为中心的任务,但无法导出显示密集BEV表示,不适用于密集感知任务,如BEV分割。因此,PETRv2中设计了一种混合查询策略,其中处理稀疏目标查询外,还提出了一种密集分割查询,每个分割查询分割特定的patch。