
BEVFormer
BEVFormer是一个一个采用纯视觉做感知任务的算法模型,其通过提取环视相机采集到的图像特征,并将提取的环视特征通过模型学习的方式转换到BEV空间(模型去学习如何将特征从图像坐标系转化到BEV坐标系),从而实现3D目标检测和地图分割任务。
BEVFormer的Pipline
BEVFormer的pipline分为下面几个部分:
- Backbone + Neck (ResNet-101-DCN +FPN)提取环视图像的多尺度特征;
- Encoder模块(包括Temporal Self-Attention模块和Spatial Cross-Attion模块)完成环视图像特征向BEV特征的建模;
- Decoder模块完成3D目标检测的分类和定位任务;
- 正负样本的定义(采用Transformer 中常用的匈牙利匹配算法,Foacal Loss + L1 loss的总损失最小);
- 损失的计算(Focal Loss分类损失 + L1 Loss回归损失);
- 反向传播,更新网络模型参数
输入数据格式
BEVFormer网络模型的输入是一个6维的张量:
(bs,queue,cam,C,H,W)
- bs:batch size大小;
- queue:连续帧的个数;由于BEVFormer采用了时序信息的思想,可以从一定程度上缓解遮挡问题,所以输入到网络模型中的数据包含当前帧及之前几帧数据;
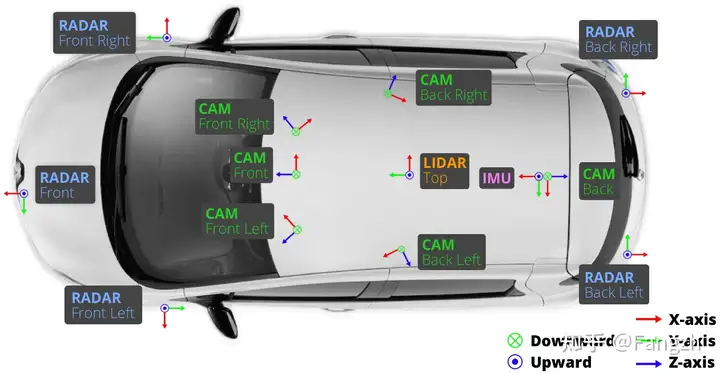
- cam:每帧中包含的图像数量,对于nuScenes数据集而言,由于一辆车带有6个环视相机传感器,可以实现360°全场景的覆盖,所以一帧会包含6个环视相机拍摄到的6张环视图片;
- C,H,W:图片的通道数、高度及宽度。
网络特征提取的目的是将每一帧对应的六张环视图像的特征提取出来,便于后续转换到 BEV 特征空间,生成 BEV 特征,在特征提取过程中,张量流的变换情况如下:
# 输入图片信息 tensor: (bs, queue, cam, c, h, w)
# 通过 for loop 方式一次获取单帧对应的六张环视图像
# 送入到 Backbone + Neck 网络提取多尺度的图像特征
for idx in range(tensor.size(1) - 1): # 利用除当前帧之外的所有帧迭代计算 `prev_bev` 特征
single_frame = tensor[:, idx, :] # (bs, cam, c, h, w)
# 将 bs * cam 看作是 batch size,将原张量 reshape 成 4 维的张量
# 待 Backbone + Neck 网络提取多尺度特征后,再把 bs * cam 的维度再拆成 bs,cam
single_frame = single_frame.reshape(bs * cam, c, h, w)
feats = Backbone(FPN(single_frame))
""" feats 是一个多尺度的特征列表 """
[0]: (bs, cam, 256, h / 8, w / 8)
[1]: (bs, cam, 256, h / 16, w / 16)
[2]: (bs, cam, 256, h / 32, w / 32)
[3]: (bs, cam, 256, h / 64, w / 64)Encoder模块
Encoder模块是为了生成BEV特征,其网络结构如下:
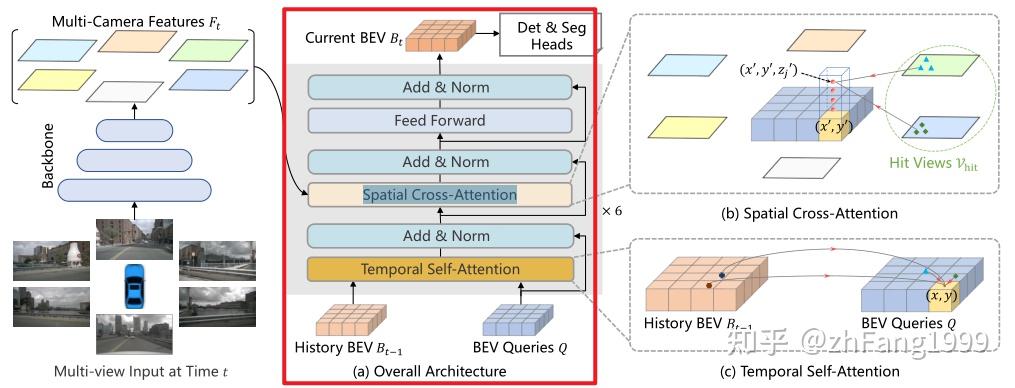
Encoder模块包含了两个子模块:Temporal Self-Attention模块和Spatial Cross-Attention模块。
这两个模块都用到了一个组件------多尺度的可变性注意力模块,该模块是将Transformer的全局注意力变为局部注意力的一个非常关键的组件,用来减少训练时间,提高Transformer的收敛速度。
多尺度可变形注意力模块与Transformer中常见的先生成Attention Map,再计算加权和的方式不同;常规而言Attention Map = Query 和Key做内积运算,将Attention Map再和Value做加权;但是由于这种方式计算量开销会比较大,所以在Deformable DETR中用局部注意力机制代替了全局注意力机制,只对几个采样点进行采样,而采样点的位置对于参考点的偏移量和每个采样点在加权时的比重均是靠Query经过Linear层学习得到的。
Temporal Self-Attention模块
功能:通过引入时序信息(History BEV)与当前时刻的BEV Query进行融合,提高BEV Query的建模能力。

对于Temporal Self-Attention模块而言,需要bev_query、bev_pos、prev_bev、ref_point、value等参数。
bev_query:一个完全learnable parameter,通过nn.Embedding()函数得到,形状shape = (200*200,256);200,200分别代表BEV特征平面的长和宽;
- History BEV
与当前BEV Queries 会首先进行Self-Attention,前者为后者BEV Queries提供先验,提前优化了该BEV Queries,方便之后与图像空间上的多尺度特征进行Cross-Attention,这样既融合了时序特征又融合了空间特征,并最终生产BEV特征。
- History BEV
bev_pose:一个完全learnable parameter,与2D检测中常见的正余弦编码方式不同,是把不同的grid位置映射到一个高维的向量空间,shape=(bs,256,200,200),代码如下:
""" bev_pose 的生成过程 """ # w, h 分别代表 bev 特征的空间尺寸 200 * 200 x = torch.arange(w, device=mask.device) y = torch.arange(h, device=mask.device) # self.col_embed 和 self.row_embed 分别是两个 Linear 层,将(200, )的坐标向高维空间做映射 x_embed = self.col_embed(x) # (200, 128) y_embed = self.row_embed(y) # (200, 128) # pos shape: (bs, 256, 200, 200) pos = torch.cat((x_embed.unsqueeze(0).repeat(h, 1, 1), y_embed.unsqueeze(1).repeat(1, w, 1)), dim=-1).permute(2, 0, 1).unsqueeze(0).repeat(mask.shape[0], 1, 1, 1)ref_point:该参数根据当前Temporal Self-Attention模块是否有pre_bev特征输入而言,会对应不同的情况,之所以会出现不同,是考虑到了前后时刻BEV特征存在不对齐的问题,BEV特征不对齐主要表现在以下两个方面:
车自身是不断运动的
上一刻和当前时刻,由于车身的不断运动,两个时刻的BEV特征在空间上是不对齐的;针对这一问题,为了实现两个特征的空间对齐,需要用到can_bus数据中有关车身自身旋转角度和偏移的信息,从而对上一时刻的BEV特征与当前时刻的BEV特征在空间上实现特征对齐;
车周围的物体也在一定范围内运动
针对车周围的物体可能在不同时刻也有移动,这部分的特征对齐就是靠网络自身的注意力模块去学习实现修正了。
综上,对于Temporal Self-Attention模块没有输入pre_bev(第一帧没有前一时刻的BEV特征)的情况,其
ref_point = ref_2d;对于存在输入pre_bev的情况,其ref_point = ref_2d +shift;涉及到的
ref_2d、shift参数,核心代码如下:"""shift 参数的生成""" # obtain rotation angle and shift with ego motion delta_x = kwargs['img_metas'][0]['can_bus'][0] delta_y = kwargs['img_metas'][0]['can_bus'][1] ego_angle = kwargs['img_metas'][0]['can_bus'][-2] / np.pi * 180 rotation_angle = kwargs['img_metas'][0]['can_bus'][-1] grid_length_y = grid_length[0] grid_length_x = grid_length[1] translation_length = np.sqrt(delta_x ** 2 + delta_y ** 2) translation_angle = np.arctan2(delta_y, delta_x) / np.pi * 180 if translation_angle < 0: translation_angle += 360 bev_angle = ego_angle - translation_angle shift_y = translation_length * \ np.cos(bev_angle / 180 * np.pi) / grid_length_y / bev_h shift_x = translation_length * \ np.sin(bev_angle / 180 * np.pi) / grid_length_x / bev_w shift_y = shift_y * self.use_shift shift_x = shift_x * self.use_shift shift = bev_queries.new_tensor([shift_x, shift_y]) # shape (2,) # 通过`旋转`和`平移`变换实现 BEV 特征的对齐,对于平移部分是通过对参考点加上偏移量`shift`体现的 if prev_bev is not None: if prev_bev.shape[1] == bev_h * bev_w: prev_bev = prev_bev.permute(1, 0, 2) if self.rotate_prev_bev: num_prev_bev = prev_bev.size(1) prev_bev = prev_bev.reshape(bev_h, bev_w, -1).permute(2, 0, 1) # sequence -> grid prev_bev = rotate(prev_bev, rotation_angle, center=self.rotate_center) prev_bev = prev_bev.permute(1, 2, 0).reshape(bev_h * bev_w, num_prev_bev, -1) """ref_2d 参数的生成,常规的 2D 网格生成的规则坐标点""" ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H - 0.5, H, dtype=dtype, device=device), torch.linspace(0.5, W - 0.5, W, dtype=dtype, device=device)) ref_y = ref_y.reshape(-1)[None] / H ref_x = ref_x.reshape(-1)[None] / W ref_2d = torch.stack((ref_x, ref_y), -1) ref_2d = ref_2d.repeat(bs, 1, 1).unsqueeze(2)value: 该参数就是对应着bev_query去查询的特征;
对于 Temporal Self-Attention 模块输入包含
prev_bev时,value = [prev_bev,bev_query],对应的参考点ref_point = [ref_2d + shift,ref_2d];如果输入不包含prev_bev时,value = [bev_query,bev_query],对应的参考点ref_point = [ref_2d,ref_2d]。内部参数:Offset、weights、Sample Location。
参数
Offset的计算是同时考虑了value[0]和bev_query的信息,在映射空间的维度上进行了concat,并基于 concat 后的特征,去计算Offset以及attention weights,涉及到的核心代码如下:""" bev_query 按照通道维度进行 concat """ query = torch.cat([value[0:1], query], -1) # (bs, 40000, 512) """ value 经过 Linear 做映射 """ value = self.value_proj(value) """ offsets 以及 attention weights 的生成过程 """ # sampling_offsets: shape = (bs, num_query, 8, 1, 4, 2) # 对 query 进行维度映射得到采样点的偏移量 sampling_offsets = self.sampling_offsets(query).view(bs, num_query, self.num_heads, self.num_levels, self.num_points, 2) # 对 query 进行维度映射得到注意力权重 attention_weights = self.attention_weights(query).view(bs, num_query, self.num_heads, self.num_levels * self.num_points) attention_weights = attention_weights.softmax(-1) # attention_weights: shape = (bs, num_query, 8, 1, 4) attention_weights = attention_weights.view(bs, num_query, self.num_heads, self.num_levels, self.num_points) """ sample location 的生成过程 通过代码可以观察到两点: 1. 通过 query 学到的 sampling_offsets 偏移量是一个绝对量,不是相对量,所以需要做 normalize; 2. 最终生成的 sampling_locations 是一个相对量; """ offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1) sampling_locations = reference_points[:, :, None, :, None, :] \ + sampling_offsets / offset_normalizer[None, None, None, :, None, :]输出bev_query
至此,Temporal Self-Attention 模块的逻辑到此结束,将生成的 bev_query 送入到后面的 Spatial Cross-Attention 模块中。
""" 各个参数的 shape 情况 1. value: (2,40000,8,32) # 2: 代表前一时刻的 BEV 特征和后一时刻的 BEV 特征,两个特征在计算的过程中是互不干扰的, # 40000: 代表 bev_query 200 * 200 空间大小的每个位置 # 8: 代表8个头,# 32: 每个头表示为 32 维的特征 2. spatial_shapes: (200, 200) # 方便将归一化的 sampling_locations 反归一化 3. level_start_index: 0 # BEV 特征只有一层 4. sampling_locations: (2, 40000, 8, 1, 4, 2) 5. attention_weights: (2, 40000, 8, 1, 4) 6. output: (2, 40000, 8, 32) """ output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations, attention_weights, self.im2col_step) """ 最后将前一时刻的 bev_query 与当前时刻的 bev_query 做平均 output = output.permute(1, 2, 0) output = (output[..., :bs] + output[..., bs:])/self.num_bev_queue
Spatial Cross-Attention模块
功能
利用Temporal Self-Attention模块输出的
bev_query,对主干网和Neck网络提取到的多尺度环视图像特征进行查询,生成BEV空间下的BEV Embedding特征;代码实现
对于Spatial Cross-Attention模块而言,与Temporal Self-Attention模块需要的参数很类似,但是不需要bev_pos参数,只需要bev_query、ref_point、value(就是concat到一起的多尺度特征),不需要bev_pose;
参数bev_query
bev_query参数来自于Temporal Self-Attention模块的输出
参数value
对于Transformer而言,由于其本身是处理文本序列的模型,而文本序列都是一组组一维的数据,所以将前面提取到的多尺度特征做flatten()处理,将所有层的特征汇聚到一起,方便之后做查询,相应代码如下:
""" 首先将多尺度的特征每一层都进行 flatten() """ for lvl, feat in enumerate(mlvl_feats): bs, num_cam, c, h, w = feat.shape spatial_shape = (h, w) feat = feat.flatten(3).permute(1, 0, 3, 2) if self.use_cams_embeds: feat = feat + self.cams_embeds[:, None, None, :].to(feat.dtype) feat = feat + self.level_embeds[None, None, lvl:lvl + 1, :].to(feat.dtype) spatial_shapes.append(spatial_shape) feat_flatten.append(feat) """ 对每个 camera 的所有层级特征进行汇聚 """ feat_flatten = torch.cat(feat_flatten, 2) # (cam, bs, sum(h*w), 256) spatial_shapes = torch.as_tensor(spatial_shapes, dtype=torch.long, device=bev_pos.device) # 计算每层特征的起始索引位置 level_start_index = torch.cat((spatial_shapes.new_zeros((1,)), spatial_shapes.prod(1).cumsum(0)[:-1])) # 维度变换 feat_flatten = feat_flatten.permute(0, 2, 1, 3) # (num_cam, sum(H*W), bs, embed_dims)ref_point
ref_3d是基于BEV空间产生的三维空间规则网格点,同时在z轴方向上人为的选择了4个坐标点。这里使用z轴,并在z轴上采样的物体意义可能是为了提取每个BEV位置处不同高度的特征,为了更好的获取在BEV空间下的(x,y)处的特征,将(x,y)的坐标进行lift,从而将BEV坐标系下的三维点映射回图像平面后可以去查询并融合更加准确的特征。
而在映射过程中,由于每个参考点映射回图像坐标系后,不会落到6个图像上,只可能落在其中的某些图像的某些位置上,所以只对这些参考点附近的位置进行采样,可以提高模型的收敛速度。
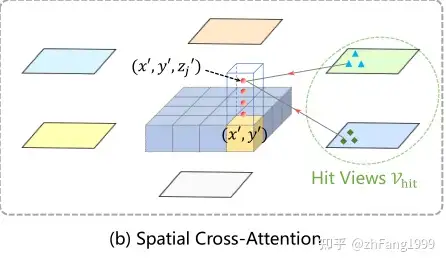
ref_3d参数生成、3D坐标向图像平面转换等过程的核心代码如下,真正用在Spatial Cross-Attention模块的参考点事下面代码中的reference_points_cam:
""" ref_3d 坐标生成 """ zs = torch.linspace(0.5, Z - 0.5, num_points_in_pillar, dtype=dtype, device=device).view(-1, 1, 1).expand(num_points_in_pillar, H, W) / Z xs = torch.linspace(0.5, W - 0.5, W, dtype=dtype, device=device).view(1, 1, W).expand(num_points_in_pillar, H, W) / W ys = torch.linspace(0.5, H - 0.5, H, dtype=dtype, device=device).view(1, H, 1).expand(num_points_in_pillar, H, W) / H ref_3d = torch.stack((xs, ys, zs), -1) # (4, 200, 200, 3) (level, bev_h, bev_w, 3) 3代表 x,y,z 坐标值 ref_3d = ref_3d.permute(0, 3, 1, 2).flatten(2).permute(0, 2, 1) # (4, 200 * 200, 3) ref_3d = ref_3d[None].repeat(bs, 1, 1, 1) # (1, 4, 200 * 200, 3) """ BEV 空间下的三维坐标点向图像空间转换的过程 代码中的`lidar2img`需要有两点需要注意 1. BEV 坐标系 这里指 lidar 坐标系 2. 这里提到的`lidar2img`是经过坐标变换的,一般分成三步 第一步:lidar 坐标系 -> ego vehicle 坐标系 第二步:ego vehicle 坐标系 -> camera 坐标系 第三部:camera 坐标系 通过相机内参 得到像素坐标系 以上这三步用到的所有平移和旋转矩阵都合并到了一起,形成了 `lidar2img` 旋转平移矩阵 同时需要注意:再与`lidar2img`矩阵乘完,还需要经过下面两步坐标系转换,才是得到了三维坐标点在二维图像平面上的点 """ # (level, bs, cam, num_query, 4) 坐标系转换第一步:reference_points_cam = torch.matmul(lidar2img.to(torch.float32), reference_points.to(torch.float32)).squeeze(-1) eps = 1e-5 bev_mask = (reference_points_cam[..., 2:3] > eps) # (level, bs, cam, num_query, 1) 坐标系转换第二步:reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3]) * eps) # reference_points_cam = (bs, cam = 6, 40000, level = 4, xy = 2) reference_points_cam[..., 0] /= img_metas[0]['img_shape'][0][1] # 坐标归一化 reference_points_cam[..., 1] /= img_metas[0]['img_shape'][0][0] # 坐标归一化 # bev_mask 用于评判某一 三维坐标点 是否落在了 二维坐标平面上 # bev_mask = (bs, cam = 6, 40000, level = 4) bev_mask = (bev_mask & (reference_points_cam[..., 1:2] > 0.0) & (reference_points_cam[..., 1:2] < 1.0) & (reference_points_cam[..., 0:1] < 1.0) & (reference_points_cam[..., 0:1] > 0.0))注意:上述得到的bev_query和reference_points_cam并不是直接用在Spatial Cross-Attention模块中,而是选择有用部分进行使用(减少模型的计算量,提高训练过程的收敛速度)
之前也有提到,并不是 BEV 坐标系下的每个三维坐标都会映射到环视相机的所有图像上,而只会映射到其中的某几张图片上,所以使用所有来自 Temporal Self-Attention 模块的所有
bev_query会消耗很大的计算量,所以这里是对bev_query进行了重新的整合,涉及的核心代码如下:indexes = [] # 根据每张图片对应的`bev_mask`结果,获取有效query的index for i, mask_per_img in enumerate(bev_mask): index_query_per_img = mask_per_img[0].sum(-1).nonzero().squeeze(-1) indexes.append(index_query_per_img) queries_rebatch = query.new_zeros([bs * self.num_cams, max_len, self.embed_dims]) reference_points_rebatch = reference_points_cam.new_zeros([bs * self.num_cams, max_len, D, 2]) for i, reference_points_per_img in enumerate(reference_points_cam): for j in range(bs): index_query_per_img = indexes[i] # 重新整合 `bev_query` 特征,记作 `query_rebatch queries_rebatch[j * self.num_cams + i, :len(index_query_per_img)] = query[j, index_query_per_img] # 重新整合 `reference_point`采样位置,记作`reference_points_rebatch` reference_points_rebatch[j * self.num_cams + i, :len(index_query_per_img)] = reference_points_per_img[j, index_query_per_img]与产生query_rebatch原因相同,获取映射到二维图像后的有效位置,对原有的reference_points进行重新整合reference_points_rebatch。
""" 获取 sampling_offsets,依旧是对 query 做 Linear 做维度的映射,但是需要注意的是 这里的 query 指代的是上面提到的 `quries_rebatch` """ # sample 8 points for single ref point in each level. # sampling_offsets: shape = (bs, max_len, 8, 4, 8, 2) sampling_offsets = self.sampling_offsets(query).view(bs, num_query, self.num_heads, self.num_levels, self.num_points, 2) attention_weights = self.attention_weights(query).view(bs, num_query, self.num_heads, self.num_levels * self.num_points) attention_weights = attention_weights.softmax(-1) # attention_weights: shape = (bs, max_len, 8, 4, 8) attention_weights = attention_weights.view(bs, num_query, self.num_heads, self.num_levels, self.num_points) """ 生成 sampling location """ offset_normalizer = torch.stack([spatial_shapes[..., 1], spatial_shapes[..., 0]], -1) reference_points = reference_points[:, :, None, None, None, :, :] sampling_offsets = sampling_offsets / offset_normalizer[None, None, None, :, None, :] sampling_locations = reference_points + sampling_offsets输出bev_embedding
将上述处理好的参数,送入多尺度可变形注意力模块中生成bev_embedding特征:
""" 1. value: shape = (cam = 6, sum(h_i * w_i) = 30825, head = 8, dim = 32) 2. spatial_shapes = ([[116, 200], [58, 100], [29, 50], [15, 25]]) 3. level_start_index= [0, 23200, 29000, 30450] 4. sampling_locations = (cam, max_len, 8, 4, 8, 2) 5. attention_weights = (cam, max_len, 8, 4, 8) 6. output = (cam, max_len, 8, 32) """ output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations, attention_weights, self.im2col_step) """最后再将六个环视相机查询到的特征整合到一起,再求一个平均值 """ for i, index_query_per_img in enumerate(indexes): for j in range(bs): # slots: (bs, 40000, 256) slots[j, index_query_per_img] += queries[j * self.num_cams + i, :len(index_query_per_img)] count = bev_mask.sum(-1) > 0 count = count.permute(1, 2, 0).sum(-1) count = torch.clamp(count, min=1.0) slots = slots / count[..., None] # maybe normalize. slots = self.output_proj(slots)以上就是 Spatial Cross-Attention 模块的整体逻辑。
将 Temporal Self-Attetion 模块和 Spatial Cross-Attention 模块堆叠在一起,并重复六次,最终得到的
BEV Embedding特征作为下游 3D 目标检测和道路分割任务的 BEV 空间特征。
Decoder模块
上述产生BEV特征的过程是用了当前输入到网络模型中除当前帧外,之前所有帧特征去迭代修正去获得pre_bev的特征;所以在利用decoder模块进行解码之前,需要对当前时刻环视的6张图片同样利用Backbone+Neck提取多尺度特征,再利用上述的
Temporal Self-Attention 模块和 Spatial Cross-Attention
模块的逻辑生成当前时刻的bev_embedding,然后将这部分特征送入到
Decoder 中进行 3D 目标检测。
如何获取预测框和分类得分
query、query_pos
query和query_pos都是可学习的。模型直接用 nn.Embedding() 生成一组(900,512)维的张量。然后将 512 维的张量分成两组,分别构成了
query = (900,256)和query_pos = (900,256)。reference_points
对于多尺度可变形注意力模块需要参考点,但在预测过程中无参考点,这需要网络学习出来,网络靠query_pos学习到的,代码如下:
reference_points = self.reference_points(query_pos) # (bs, 900, 3) 3 代表 (x, y, z) 坐标 reference_points = reference_points.sigmoid() # absolute -> relative init_reference_out = reference_pointsDecoder逻辑
在获取到需要用到的
query、query_pos、reference_points参数后,后面的逻辑有些类似 Deformabe DETR 的 Decoder 过程,简单概括如下几点:利用
query和query_pos去做常规的 Self-Attention 运算更新query;利用 Self-Attention 得到的 query,之前获得的
bev_embedding作为value,query_pos,由 query生成的reference_points(虽然生成的x,y,z参考点位置,但是 BEV Embedding 是二维的,所以参考点只选择了前两维)仿照 Deformable Attention Module 的 pipeline 做可变形注意力;可变形注意力核心代码如下:
""" 由 query 生成 sampling_offsets 和 attention_weights """ sampling_offsets = self.sampling_offsets(query).view( bs, num_query, self.num_heads, self.num_levels, self.num_points, 2) # (bs, 900, 8, 1, 4, 2) attention_weights = self.attention_weights(query).view( bs, num_query, self.num_heads, self.num_levels * self.num_points) # (bs, 900, 8, 4) attention_weights = attention_weights.softmax(-1) attention_weights = attention_weights.view(bs, num_query, self.num_heads, self.num_levels, self.num_points) # (bs, 900, 8, 1, 4) """ sampling_offsets 和 reference_points 得到 sampling_locations """ offset_normalizer = torch.stack( [spatial_shapes[..., 1], spatial_shapes[..., 0]], -1) sampling_locations = reference_points[:, :, None, :, None, :] \ + sampling_offsets \ / offset_normalizer[None, None, None, :, None, :] """ 多尺度可变形注意力模块 """ # value: shape = (bs, 40000, 8, 32) # spatial_shapes = (200, 200) # level_start_index = 0 # sampling_locations = (bs, 900, 8, 1, 4, 2) # attention_weights = (bs, 900, 8, 1, 4) # output = (bs, 900, 256) output = MultiScaleDeformableAttnFunction.apply(value, spatial_shapes, level_start_index, sampling_locations, attention_weights, self.im2col_step)在获得查询到的特征后,会利用回归分支(FFN 网络)对提取的特征计算回归结果,预测 10 个输出;
我的理解这 10 个维度的含义为:[xc,yc,w,l,zc,h,rot.sin(),rot.cos(),vx,vy];[预测框中心位置的x方向偏移,预测框中心位置的y方向偏移,预测框的宽,预测框的长,预测框中心位置的z方向偏移,预测框的高,旋转角的正弦值,旋转角的余弦值,x方向速度,y方向速度];
然后根据预测的偏移量,对参考点的位置进行更新,为级联的下一个 Decoder 提高精修过的参考点位置,核心代码如下:
if reg_branches is not None: # update the reference point. tmp = reg_branches[lid](output) # (bs, 900, 256) -> (bs, 900, 10) 回归分支的预测输出 assert reference_points.shape[-1] == 3 new_reference_points = torch.zeros_like(reference_points) # 预测出来的偏移量是绝对量 new_reference_points[..., :2] = tmp[..., :2] + inverse_sigmoid(reference_points[..., :2]) # 框中心处的 x, y 坐标 new_reference_points[..., 2:3] = tmp[..., 4:5] + inverse_sigmoid(reference_points[..., 2:3]) # 框中心处的 z 坐标 # 参考点坐标是一个归一化的坐标 new_reference_points = new_reference_points.sigmoid() reference_points = new_reference_points.detach() """ 最后将每层 Decoder 产生的特征 = (bs, 900, 256),以及参考点坐标 = (bs, 900, 3) 保存下来。 """ if self.return_intermediate: intermediate.append(output) intermediate_reference_points.append(reference_points)然后将层级的
bev_embedding特征以及参考点通过 for loop 的形式,一次计算每个 Decoder 层的分类和回归结果:bev_embed, hs, init_reference, inter_references = outputs hs = hs.permute(0, 2, 1, 3) # (decoder_level, bs, 900, 256) outputs_classes = [] outputs_coords = [] for lvl in range(hs.shape[0]): if lvl == 0: reference = init_reference else: reference = inter_references[lvl - 1] reference = inverse_sigmoid(reference) outputs_class = self.cls_branches[lvl](hs[lvl]) # (bs, 900, num_classes) tmp = self.reg_branches[lvl](hs[lvl]) # (bs, 900, 10) assert reference.shape[-1] == 3 tmp[..., 0:2] += reference[..., 0:2] # (x, y) tmp[..., 0:2] = tmp[..., 0:2].sigmoid() tmp[..., 4:5] += reference[..., 2:3] tmp[..., 4:5] = tmp[..., 4:5].sigmoid() tmp[..., 0:1] = (tmp[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0]) tmp[..., 1:2] = (tmp[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1]) tmp[..., 4:5] = (tmp[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2]) outputs_coord = tmp outputs_classes.append(outputs_class) outputs_coords.append(outputs_coord)
正负样本的定义
正负样本的定义用到的就是匈牙利匹配算法,分类损失和类似回归损失的总损失和最小;
分类损失的计算代码如下:
cls_pred = cls_pred.sigmoid() # calculate the neg_cost and pos_cost by focal loss.
neg_cost = -(1 - cls_pred + self.eps).log() * (1 - self.alpha) * cls_pred.pow(self.gamma)
pos_cost = -(cls_pred + self.eps).log() * self.alpha * (1 - cls_pred).pow(self.gamma)
cls_cost = pos_cost[:, gt_labels] - neg_cost[:, gt_labels]
cls_cost = cls_cost * self.weight类回归损失的计算代码如下:
这里介绍一下,gt_box 的表示方式,gt_box 的维度是九维的,分别是 [xc,yc,zc,w,l,h,rot,vx,vy];而预测结果框的维度是十维的,所以要对 gt_box 的维度进行转换,转换为的维度表示为 [xc,yc,w,l,cz,h,rot.sin(),rot.cos(),vx,vy]
对应代码如下:
cx = bboxes[..., 0:1]
cy = bboxes[..., 1:2]
cz = bboxes[..., 2:3]
w = bboxes[..., 3:4].log()
l = bboxes[..., 4:5].log()
h = bboxes[..., 5:6].log()
rot = bboxes[..., 6:7]
vx = bboxes[..., 7:8]
vy = bboxes[..., 8:9]
normalized_bboxes = torch.cat((cx, cy, w, l, cz, h, rot.sin(), rot.cos(), vx, vy), dim=-1)计算类回归损失(L1 Loss)
这里有一点需要注意的是,在正负样本定义中计算 L1 Loss 的时候,只对前预测框和真值框的前 8 维计算损失
self.reg_cost(bbox_pred[:, :8], normalized_gt_bboxes[:, :8])