
Attention
一、注意力机制:Attention
1.1什么是注意力机制?
我们先来看一张图片

那么,大家的目光是更多注意在美少女古河渚身上,还是花草风景身上呢?可能对于热爱动漫的人来说他会关注logo------CLANNAD 1和主人公古河渚,对于喜欢花的人来说可能更关注樱花,对于喜欢制服的人来说可能更关注jk装......
再举几个例子:
- 看人-->看脸
- 看文章-->看标题
- 看段落-->看开头
注意力机制其实是源自于人对于外部信息的处理能力。由于每一时刻接受的信息都是无比庞大且复杂万分的,远远超过了人脑的处理能力,因此人在处理信息的时候,会将注意力放在需要关注的信息上,对于其他无关的外部信息进行过滤,这种处理方式被称为注意力机制。
通俗而言,注意力对于人而言可以理解为“关注度”,对于没有感情的机器而言就是赋予多少权重(0-1间的小数),越重要的地方或者越相关的地方就赋予越高的权重。
1.2如何运用注意力机制?
1.2.1 Query、Key和Value
首先,三者概念:
- 查询(Query):是指查询的范围,自主提示,即主观意识的特征向量
- 键(Key):是被对比的项,非自主提示,即物体的突然出特征信息向量
- 值(Value):是代表物体自身的特征向量,通常与Key成对出现
注意力机制是通过Query与Key的注意力汇聚(给定一个Query,计算Query与Key的相关性,然后根据该相关性去找到最合适的Value)实现对Value的注意力权重分配,生成最终的输出结果。

举例子而言:
- 淘宝购物,输入关键词(男鞋),这个就是Query
- 搜素系统会根据这个关键词去查找一些列相关的Key(商品名、图片)
- 最后系统会将相应的Value(具体鞋子)返回给你
上述例子中,Query,Key和Value的每个属性虽然在不同的空间,但其实它们是有一定的潜在关系,也就是说通过某种变换,可以使得三者的属性在一个相近的空间中。
1.2.2 注意力机制计算过程
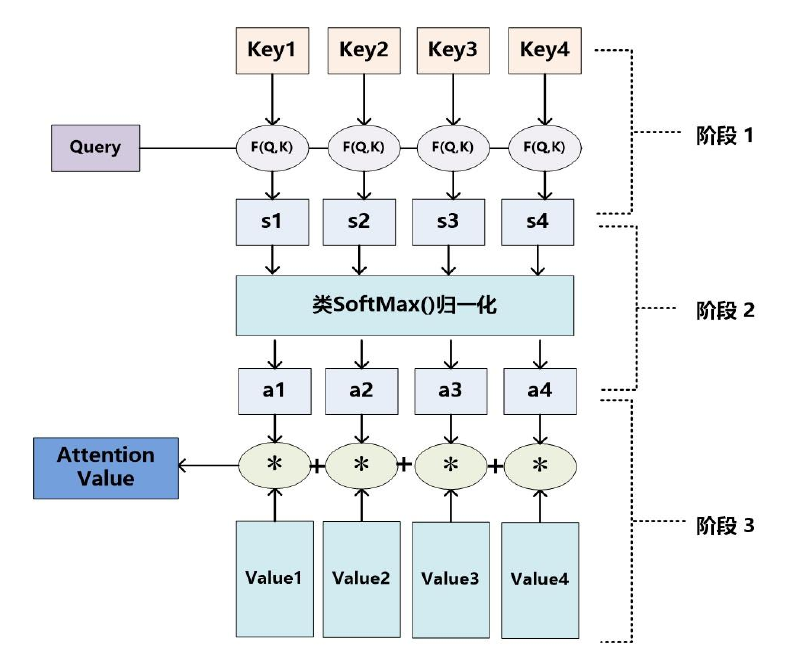
输入Query、Key、Value:
第一步:计算Query和Key间相似度(常见方法:点积、余弦相似度、MLP网络),得到注意力得分:
点积:
Cosine 相似性:
MLP网络
第二步:对注意力得分进行缩放scale(除以维度的根号),再softmax(),一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过softmax的内在机制更加突出重要元素的权重。一般采用如下公式计算:
第三步:根据权重系数对Value值进行加权求和,得到Attention Value(此时的V是具有一些注意力信息的,更重要的信息更关注,不重要的信息被忽视了)
这三个步可以用下图表示:
二、自注意力机制:Self-Attention
2.1什么是自注意力机制
自注意机制是注意力机制的一种,它要解决的实际问题是神经网络接收的输入是很多大小不一的向量,并且不同向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如,在语义分析中多个向量对应一个标签。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。不是输入语句与输出语句之间的注意力机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的注意力机制。
注意力机制和自注意力机制的区别:
(1)注意力机制的Q和K是不同来源的,例如,在Encoder-Decoder模型中,K是Encoder中的元素,而Q是Decoder中的元素。在中译英模型中,Q是中文单词特征,而K则是英文单词特征。
(2)自注意力机制的Q和K则都是来自于同一组的元素,例如,在Encoder-Decoder模型中,Q和K都是Encoder中的元素,即Q和K都是中文特征,相互之间做注意力汇聚。也可以理解为同一句话中的词元或者同一张图像中不同的patch,这都是一组元素内部相互做注意力机制,因此,自注意力机制(self-attention)也被称为内部注意力机制(intra-attention)。
2.2如何运用自注意力机制
大体上步骤和注意力机制是一样的。
First:得到Q,K,V的值
对于每一个向量x,分别乘上三个系数
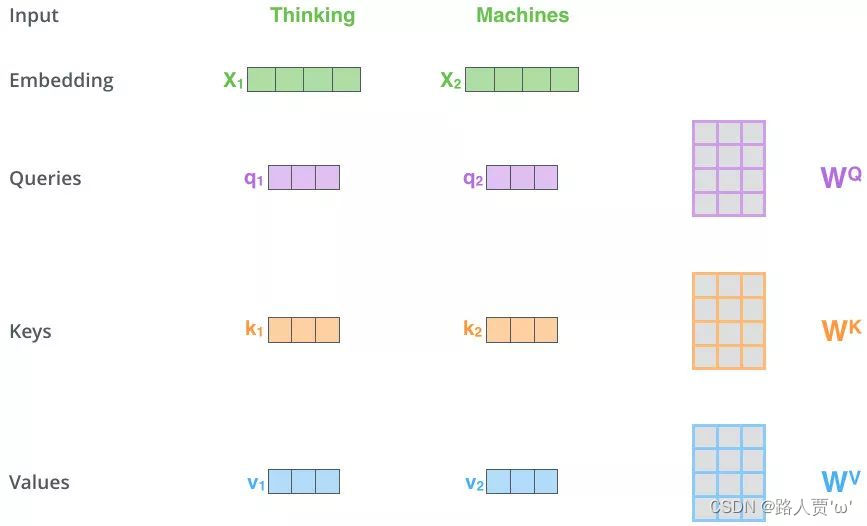
Second:Matmul
利用得到的Q和K计算每两个向量之间的相关性,一般采用点积计算,为每个向量计算一个socre:sa:

Third: Scale+Softmax
将刚得到的相似度除以
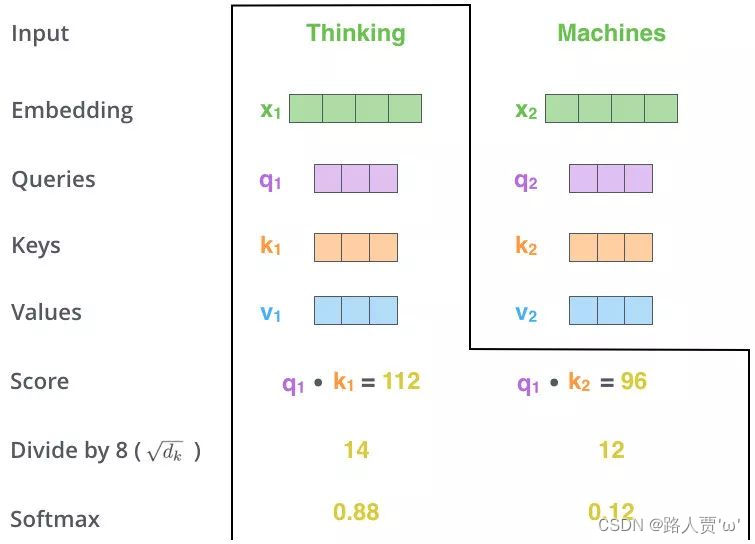
Fourth:Matmul
使用刚得到的权重矩阵,与V相乘,计算加权求和。

以上是对Thinking Machines这句话进行自注意力的全过程,最终得到z1和z2两个新向量。
其中z1表示的是thinking这个词向量的新的向量表示(通过thinking这个词向量,去查询和thinking machine这句话里面每个单词和thinking之间的相似度)。
也就是说新的z1依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息。
2.3 自注意力机制的问题
自注意力机制的原理是筛选重要信息,过滤不重要信息,这就导致其有效信息的抓取能力会比CNN小一点。这是因为自注意力机制相比CNN,无法利用图像本身具有的尺度、平移不变形,以及图像的特征局部性这些先验知识,只能通过大量数据进行学习。这就导致自注意力机制只能在大数据的基础上才能有效地建立准确的全局关系,而在小数据的情况下,其效果不如CNN。
三、多头注意力机制:Multi-Head Self-Attention
3.1为什么用多头注意力机制
自注意力机制的缺陷:模型对当前未知的信息进行编码时,会过度将注意力集中于自身的位置,有效信息抓取能力会差一点,会有才有了多头注意力机制。
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,补货序列内各种范围的依赖关系(例如:短距离依赖和长距离依赖关系)。因此,允许注意力机制组合使用查询、键、值的不同子空间表示(representation subspaces)可能是有益的。
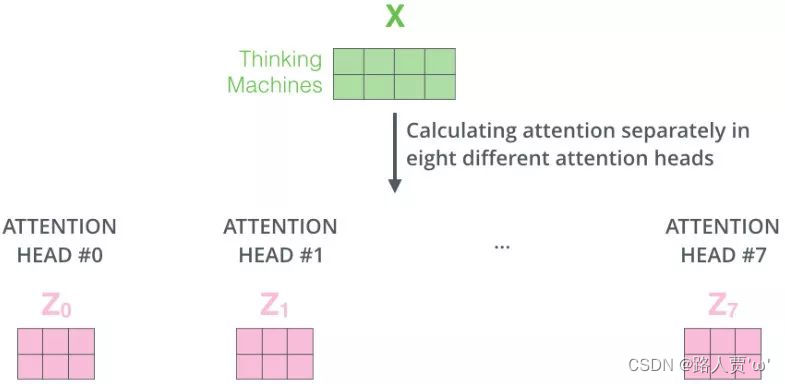
为此,与其使用单独一个注意力汇聚,我们可以用独立学习到的h组(一般h=8)不同的线性投影(linear projections)来变换查询、键和值。然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。最后,将这h个注意力汇聚的输出拼接到一起,并通过另一个可学习的线性投影进行变换,以生成最终输出。这种设计被称为多头注意力(multi-head attention)。
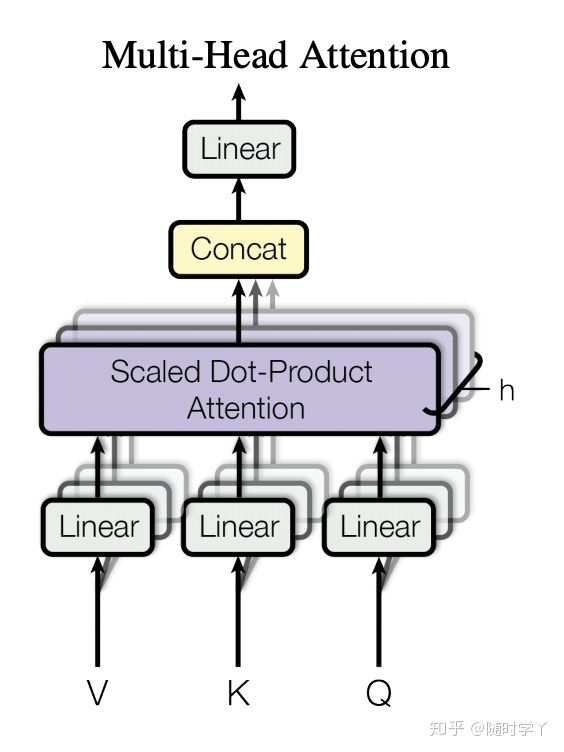
3.2如何运用多头注意力机制
First:定义多组W,生成多组Q,K,V
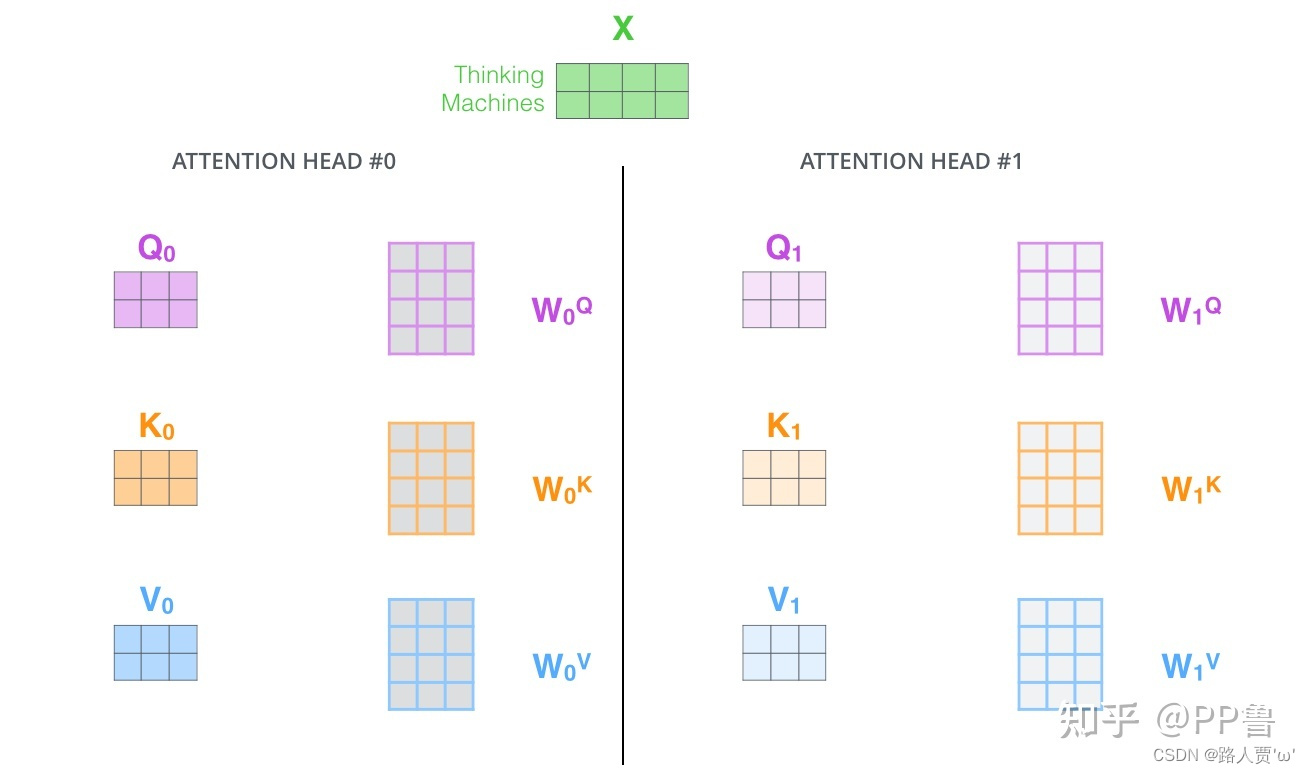
Second:定义8组参数
对应8个single head,对应8组
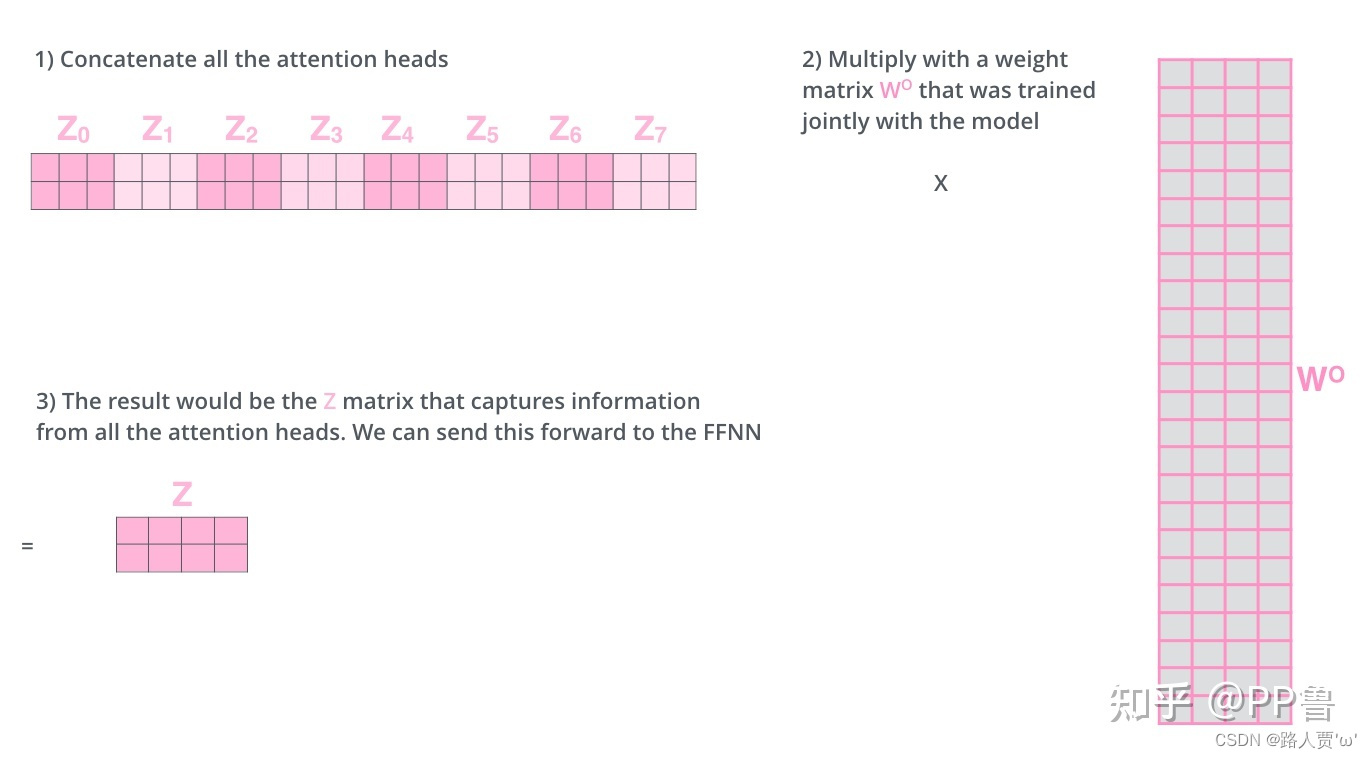
Third:将多组输出拼接后乘以矩阵W0以降维
首先在输出到下一层前,我们需要将Z0-Z7concat到一起,乘以矩阵W0做一次线性变换进行降维
完整流程如下:
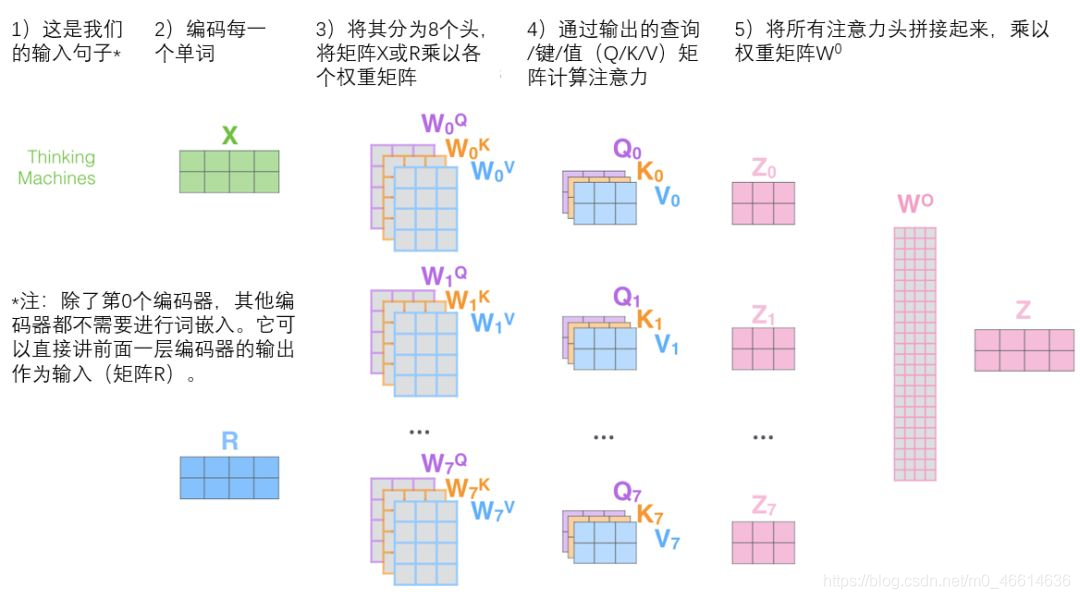
【注意】对于上图中的第2)步,当前为第一层时,直接对输入词进行编码,生成词向量X;当前为后续层时,直接使用上一层输出。
3.3代码实现多头注意力机制
在实现过程中,我们选择了缩放的“点-积”注意力作为每一个注意力头。为了避免计算成本和参数数量的显著增长,我们设置了
import math
import torch
from torch import nn
from d2l import torch as d2l
def transpose_qkv(X,num_heads):
# 输入 `X` 的形状: (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`).
# 输出 `X` 的形状: (`batch_size`, 查询或者“键-值”对的个数, `num_heads`,`num_hiddens` / `num_heads`)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出 `X` 的形状: (`batch_size`, `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
X = X.permute(0, 2, 1, 3)
# `output` 的形状: (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X,num_heads):
"""逆转 `transpose_qkv` 函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
class MultiHeadAttention(nn.Module):
def __init__(self,key_size,query_size,value_size,num_hiddens,
num_heads,dropout,bias=False,**kwargs):
super(MultiHeadAttention,self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size,num_hiddens,bias=bias) # 将输入映射为(batch_size,query_size/k-v size,num_hidden)大小的输出
self.W_k = nn.Linear(key_size,num_hiddens,bias=bias)
self.W_v = nn.Linear(value_size,num_hiddens,bias=bias)
self.W_o = nn.Linear(num_hiddens,num_hiddens,bias=bias)
def forward(self,queries,keys,values,valid_lens):
# `queries`, `keys`, or `values` 的形状:
# (`batch_size`, 查询或者“键-值”对的个数, `num_hiddens`)
# `valid_lens` 的形状:
# (`batch_size`,) or (`batch_size`, 查询的个数)
# 经过变换后,输出的 `queries`, `keys`, or `values` 的形状:
# (`batch_size` * `num_heads`, 查询或者“键-值”对的个数,`num_hiddens` / `num_heads`)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads) # 将多个头的数据堆叠在一起,然后进行计算,从而不用多次计算
if valid_lens is not None:
valid_lens = torch.repeat_interleave(valid_lens,
repeats=self.num_heads,
dim=0)
output = self.attention(queries,keys,values,valid_lens) # output->(10,4,20)
# return output
output_concat = transpose_output(output,self.num_heads) # output_concat -> (2,4,100)
return self.W_o(output_concat)
让我们使用键和值相同的小栗子来测试我们编写的MultiHeadAttention类。多头注意力输出的形状是(batch_size、num_queries、num_hiddens)。
# 线性变换的输出为100个,5个头
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
batch_size, num_queries, num_kvpairs, valid_lens = 2, 4, 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens)) # query(2,4,100)
Y = torch.ones((batch_size, num_kvpairs, num_hiddens)) # key和value (2,6,100)
output = attention(X, Y, Y, valid_lens) # 输出大小与输入的query的大小相同
output.shapetorch.Size([2, 4, 100])