
Attention:从NLP到CV再到BEV
一、Transformer
Transformer源于17年谷歌的文章Attention Is All You Need“”
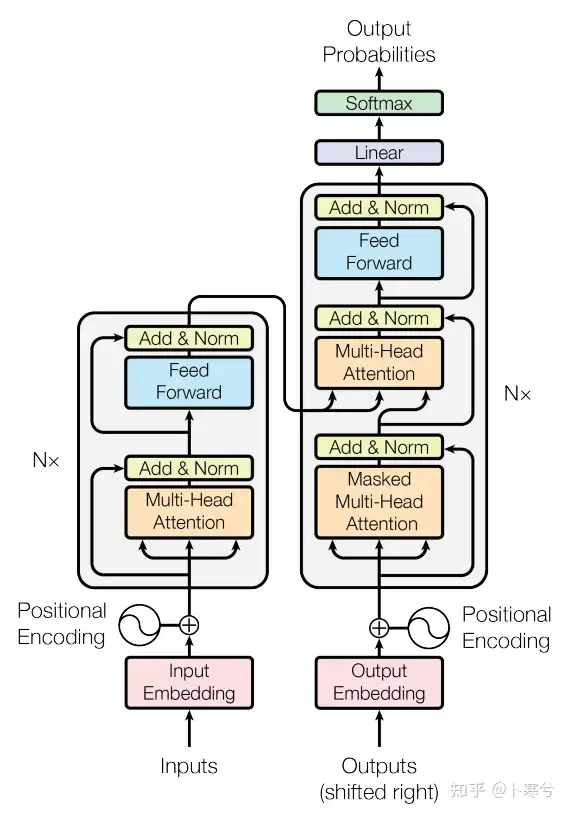
Transformer最开始应用于NLP领域的机器翻译任务。
它是一个编码器-解码器结构:编码器将原始语言的句子作为输入并生成基于注意力的表征,解码器则关注编码信息并以自回归方式生成翻译的句子。
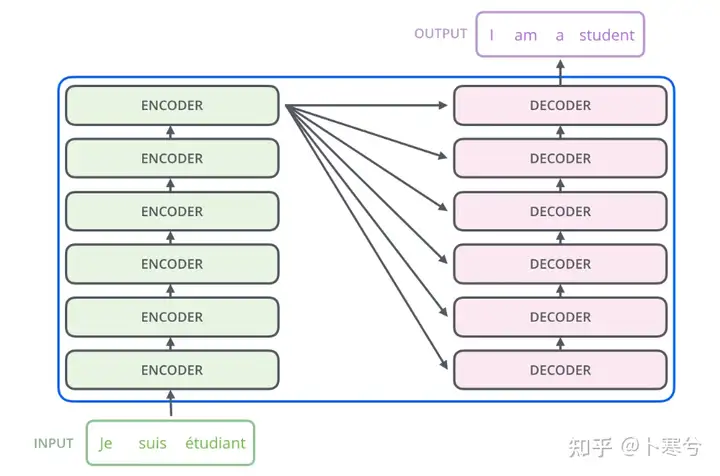
Transformer中最重要的是Attention机制。
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。

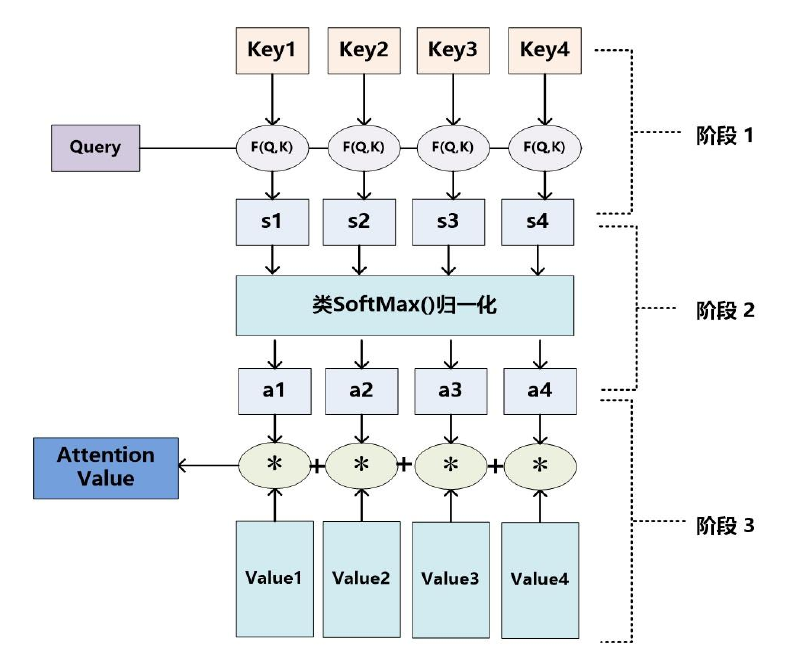
Attention机制的实质其实就是一个寻址(addressing)的过程,如下图所示:给定一个和任务相关的查询Query向量 q,通过计算与Key的注意力分布并附加在Value上,从而计算Attention Value,这个过程实际上是Attention机制缓解神经网络模型复杂度的体现:不需要将所有的N个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。

举个例子:
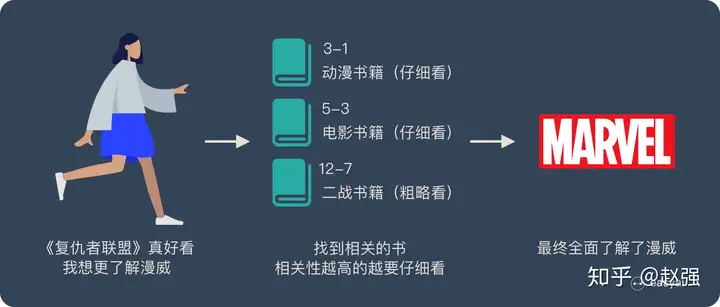
图书管(source)里有很多书(value),为了方便查找,我们给书做了编号(key)。当我们想要了解漫威(query)的时候,我们就可以看看那些动漫、电影、甚至二战(美国队长)相关的书籍。
为了提高效率,并不是所有的书都会仔细看,针对漫威来说,动漫,电影相关的会看的仔细一些(权重高),但是二战的就只需要简单扫一下即可(权重低)。
当我们全部看完后就对漫威有一个全面的了解了。
Attention 原理的3步分解:
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
self-attention
寻找一段文本内部不同部分之间的关系来构建这段文本的表征。

上图显示的就是当算法处理到红色字的表征时,它应该给文中其他文字的表征多大的注意力权重。
Transformers目标检测,端到端的DETR

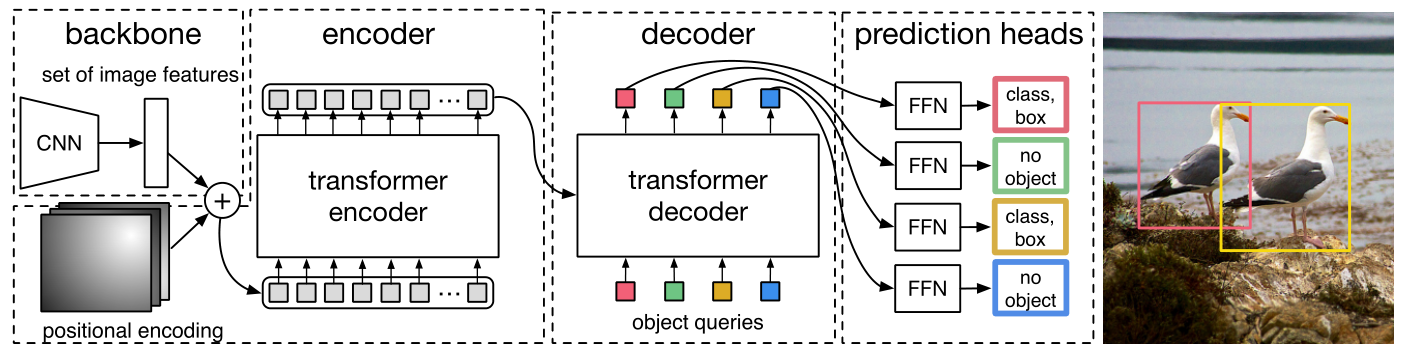
DETR摒弃了以往的生成Anchors和NMS环节,我们知道,生成Anchors即为生成一系列的框,再由CNN判断框内是否有目标及其对应的类别,而NMS则是将多余重复的框删减掉。而DETR将目标检测视为集合预测的问题,也即预测最终所需的各个目标的框及类别。直白点,就是希望通过向网络输入图片,让网络直接输出物体最终的框及其类别,这样便少了生成Anchors及NMS的环节。
这篇文章让网络生成固定数量N(原文N取100)个预测,每个预测都包含一个框及其类别。但不同于以往可能有多个预测是属于同一物体(也即得通过NMS来消除框),这里的预测,对于图片上的每个物体有且仅有一个框与之对应,而对于多于的预测,则直接归为背景类(no object)。
如上图,大概流程为,先将图片通过CNN提取特征,再通过transformer直接输出固定数量为N(原文中N取100,而N则是远大于一张图片中包含的物体数量)的预测框及其类别(不再有Anchors生成以及NMS环节)。而这N个框,每个框要么与物体唯一对应,要么直接归为背景类(no object)。假设我们现在有一张图片,图片上有2个物体,则最终预测的100个框中,将有2个为物体框,剩余的98个为背景框(不会输出)。
下图为最后一个Encoder Layer的attention可视化,Encoder已经分离了instances,简化了Decoder的对象提取和定位。

类似于可视化编码器注意力,作者在下图中可视化解码器注意力,用不同的颜色给每个预测对象的注意力图着色。观察到,解码器的attention相当局部,这意味着它主要关注对象的四肢,如头部或腿部。我们假设,在编码器通过全局关注分离实例之后,解码器只需要关注极端来提取类和对象边界。

DETR模型弊端
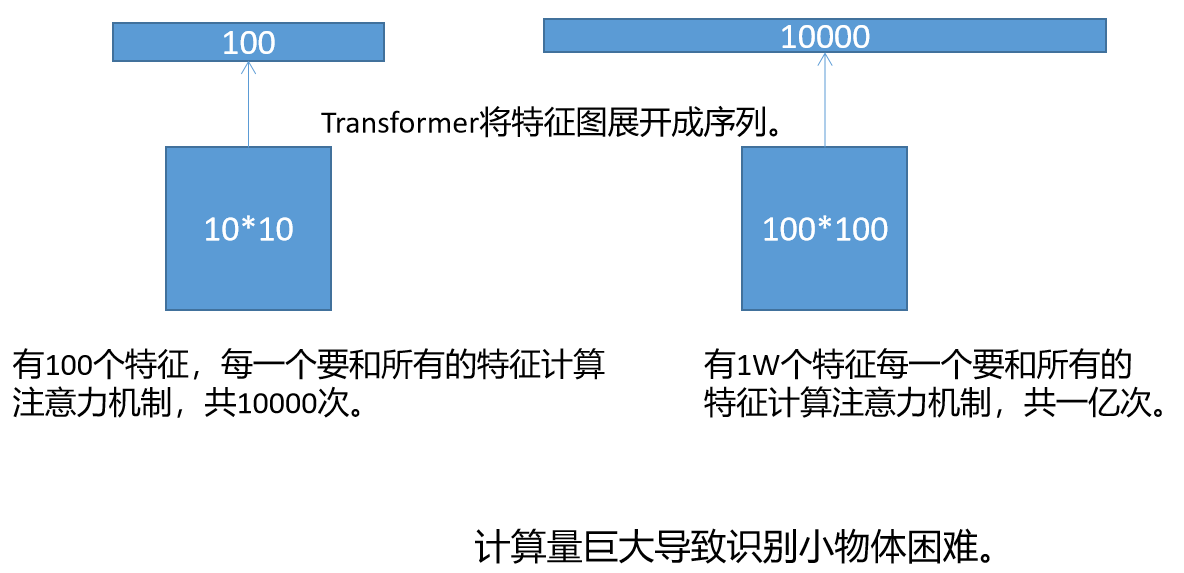
如果用10*10的特征图表示一张图片,即一张图片划分成100个Patch,那么就有100个特征向量,每一个特征向量要和所有的特征向量计算注意力机制,所以计算一次注意力机制要100*100=10000次。
如果用100*100的特征图表示一张图片,即一张图片划分成10000个Patch,那么就有10000个特征向量,每一个特征向量要和所有的特征向量计算注意力机制,所以计算一次注意力机制要10000*100000=1亿次。由此可见,每一个Patch的边长缩小10倍,计算量要增加一万倍。因为识别小物体有恰恰需要划分更小的Patch,因此DETR的小物体识别能力有限。
Transformer在BEV上的应用------BEVFormer
其网络结构如下:
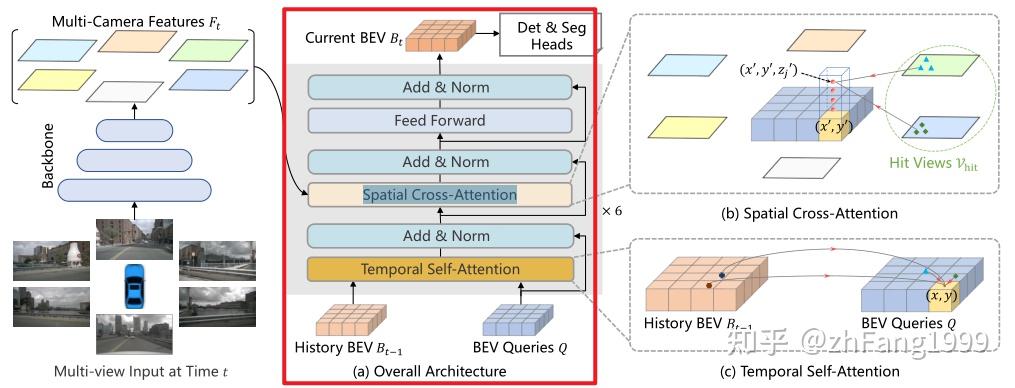
Encoder模块包含了两个子模块:Temporal Self-Attention模块和Spatial Cross-Attention模块。
这两个模块都用到了一个组件------多尺度的可变性注意力模块,该模块是将Transformer的全局注意力变为局部注意力的一个非常关键的组件,用来减少训练时间,提高Transformer的收敛速度。
多尺度可变形注意力模块与Transformer中常见的先生成Attention Map,再计算加权和的方式不同;常规而言Attention Map = Query 和Key做内积运算,将Attention Map再和Value做加权;但是由于这种方式计算量开销会比较大,所以在Deformable DETR中用局部注意力机制代替了全局注意力机制,只对几个采样点进行采样,而采样点的位置对于参考点的偏移量和每个采样点在加权时的比重均是靠Query经过Linear层学习得到的。
Temporal Self-Attention模块通过引入时序信息(History BEV)与当前时刻的BEV Query进行融合,提高BEV Query的建模能力。

Spatial Cross-Attention模块利用Temporal
Self-Attention模块输出的bev_query,对主干网和Neck网络提取到的多尺度环视图像特征进行查询,生成BEV空间下的BEV
Embedding特征

上述产生BEV特征的过程是用了当前输入到网络模型中除当前帧外,之前所有帧特征去迭代修正去获得pre_bev的特征;所以在利用decoder模块进行解码之前,需要对当前时刻环视的6张图片同样利用Backbone+Neck提取多尺度特征,再利用上述的
Temporal Self-Attention 模块和 Spatial Cross-Attention
模块的逻辑生成当前时刻的bev_embedding,然后将这部分特征送入到
Decoder 中进行 3D 目标检测。