
MMDetection整体构建流程二
MMDetection 整体构建流程(二)
本文核心内容是按照抽象到具体方式,从多个层次进行训练和测试流程深入解析,从最抽象层讲起,到最后核心代码实现,希望帮助大家更容易理解 MMDetection 开源框架整体构建细节
一、第一层整体抽象
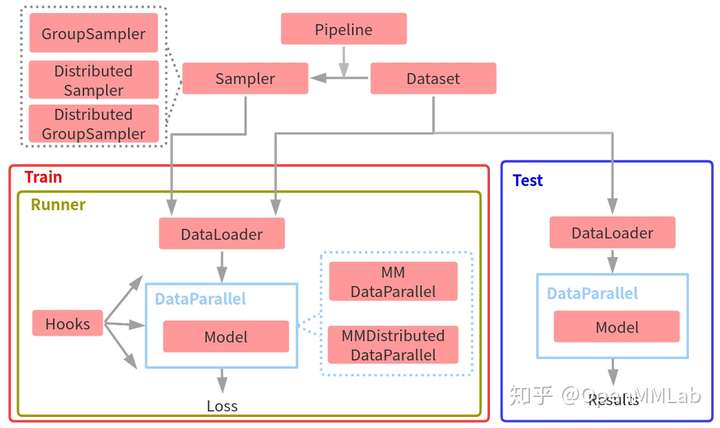
上图为 MMDetection 框架整体训练和测试抽象流程图。按照数据流过程,训练流程可以简单总结为:
- 给定任何一个数据集,首先需要构建Dataset类,用于迭代输出数据
- 在迭代输出数据的时候需要通过数据pipeline对数据进行各种处理,最典型的处理流是训练中的数据增强操作,测试中的数据预处理等
- 通过Sampler采样器可以控制Dataset输出的数据顺序,最常用的是随机采样器RandomSampler。由于Dataset中输出的图片大小不一样,为了尽可能减少后续组成batch时pad的像素个数,MMDetection引入了分组采样器GroupSampler和DistributedGroupSampler,相当于在RandomSampler基础上额外新增了根据图片宽高比进行group功能
- 将Sampler和Dataset都输入给DataLoader,然后通过DataLoader输出已组成batch的数据,作为Model的输入
- 对于任何一个Model,为了方便处理数据流及分布式需求,MMDetection引入了两个Model的上层封装:单机版本MMDataParallel、分布式(单机多卡或多机多卡)版本MMDistributedDataParallel
- Model运行后会输出loss及其他一些信息,会通过logger进行保存或者可视化
- 为了更好地解耦,方便地获取各个组件之间依赖和灵活扩展,MMDetection引入了Runner类进行全生命周期管理,并且通过Hook方便的获取、修改和拦截任何生命周期数据流,扩展非常便捷
而测试流程就比较简单了,直接对 DataLoader 输出的数据进行前向推理即可,还原到最终原图尺度过程也是在 Model 中完成。
以上就是 MMDetection 框架整体训练和测试抽象流程,上图不仅仅反映了训练和测试数据流,而且还包括了模块和模块之间的调用关系。对于训练而言,最核心部分应该是 Runner,理解了 Runner 的运行流程,也就理解了整个 MMDetection 数据流。
二、第二层模块抽象
在总体把握了整个MMDetection框架训练和测试流程后,下个层次是每个模块内部抽象流程,主要包括pipeline、DataParallel、Model、Runner和Hooks。
2.1 Pipeline
Pipeline 实际上由一系列按照插入顺序运行的数据处理模块组成,每个模块完成某个特定功能,例如 Resize,因为其流式顺序运行特性,故叫做 Pipeline。
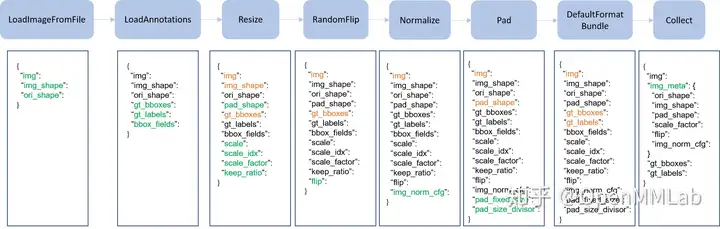
上图是一个非常典型的训练流程 Pipeline,每个类都接收字典输入,输出也是字典,顺序执行,其中绿色表示该类运行后新增字段,橙色表示对该字段可能会进行修改。如果进一步细分的话,不同算法的 Pipeline 都可以划分为如下部分:
- 图片和标签加载,通常用的类是 LoadImageFromFile 和 LoadAnnotations
- 数据前处理,例如统一 Resize
- 数据增强,典型的例如各种图片几何变换等,这部分是训练流程特有,测试阶段一般不采用(多尺度测试采用其他实现方式)
- 数据收集,例如 Collect
在 MMDetection 框架中,图片和标签加载和数据后处理流程一般是固定的,用户主要可能修改的是数据增强步骤,目前已经接入了第三方增强库 Albumentations,可以按照示例代码轻松构建属于你自己的数据增强 Pipeline。
在构建自己的 Pipeline 时候一定要仔细检查你修改或者新增的字典 key 和 value,因为一旦你错误地覆盖或者修改原先字典里面的内容,代码也可能不会报错,如果出现 bug,则比较难排查。
2.2 DataParallel 和 Model
在 MMDetection 中 DataLoader 输出的内容不是 pytorch 能处理的标准格式,还包括了 DataContainer 对象,该对象的作用是包装不同类型的对象使之能按需组成 batch。在目标检测中,每张图片 gt bbox 个数是不一样的,如果想组成 batch tensor,要么你设置最大长度,要么你自己想办法组成 batch。而考虑到内存和效率,MMDetection 通过引入 DataContainer 模块来解决上述问题,但是随之带来的问题是 pytorch 无法解析 DataContainer 对象,故需要在 MMDetection 中自行处理。
解决办法其实非常多,MMDetection 选择了一种比较优雅的实现方式:MMDataParallel 和 MMDistributedDataParallel。具体来说,这两个类相比 PyTorch 自带的 DataParallel 和 DistributedDataParallel 区别是:
- 可以处理 DataContainer 对象
- 额外实现了
train_step()和val_step()两个函数,可以被 Runner 调用
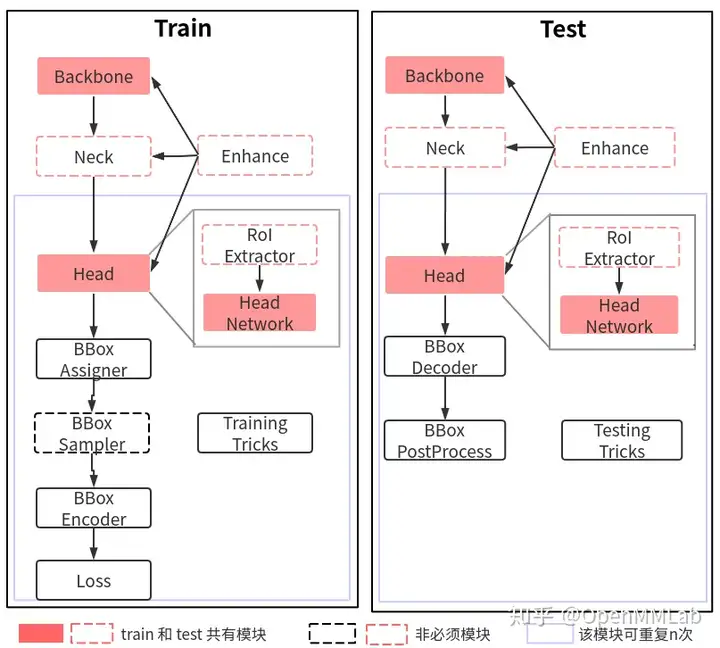
Model如下:
2.3 Runner 和 Hooks
对于任何一个目标检测算法,都需要包括优化器、学习率设置、权重保存等等组件才能构成完整训练流程,而这些组件是通用的。为了方便 OpenMMLab 体系下的所有框架复用,在 MMCV 框架中引入了 Runner 类来统一管理训练和验证流程,并且通过 Hooks 机制以一种非常灵活、解耦的方式来实现丰富扩展功能。
下面列出了在 MMDetection 几个非常重要的 hook 以及其作用的生命周期:
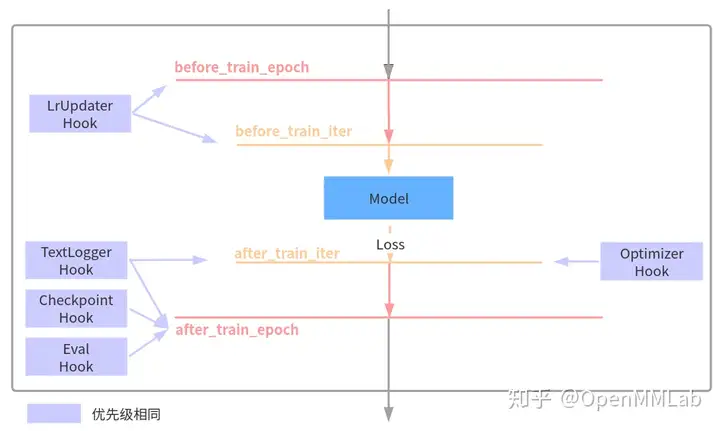
例如 CheckpointHook 在每个训练 epoch 完成后会被调用,从而实现保存权重功能。用户也可以将自己定制实现的 Hook 采用上述方式绘制,对理解整个流程或许有帮助。
三、第三层代码抽象
前面两层抽象分析流程,基本上把整个 MMDetection 的训练和测试流程分析完了,下面从具体代码层面进行抽象分析。
3.1 训练和测试整体代码抽象流程
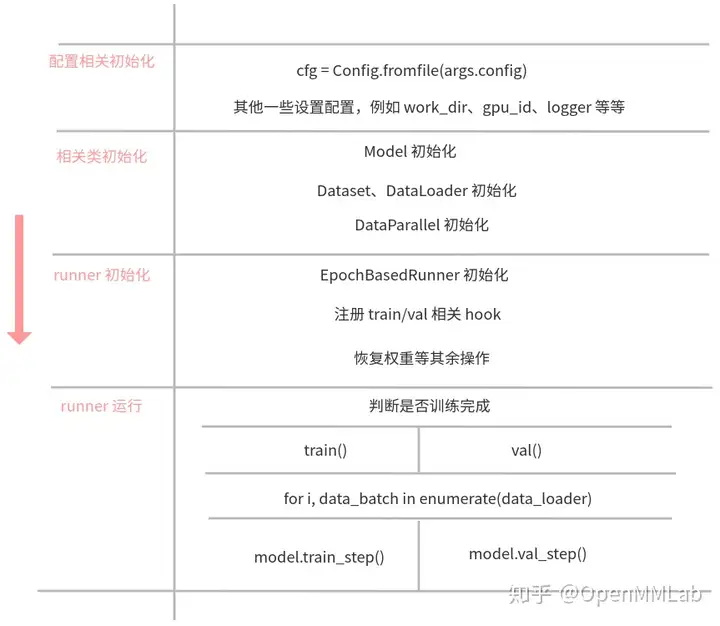
上图为训练和验证的和具体代码相关的整体抽象流程,对应到代码上,其核心代码如下:
#=================== tools/train.py ==================
# 1.初始化配置
cfg = Config.fromfile(args.config)
# 2.判断是否为分布式训练模式
# 3.初始化 logger
logger = get_root_logger(log_file=log_file, log_level=cfg.log_level)
# 4.收集运行环境并且打印,方便排查硬件和软件相关问题
env_info_dict = collect_env()
# 5.初始化 model
model = build_detector(cfg.model, ...)
# 6.初始化 datasets
#=================== mmdet/apis/train.py ==================
# 1.初始化 data_loaders ,内部会初始化 GroupSampler
data_loader = DataLoader(dataset,...)
# 2.基于是否使用分布式训练,初始化对应的 DataParallel
if distributed:
model = MMDistributedDataParallel(...)
else:
model = MMDataParallel(...)
# 3.初始化 runner
runner = EpochBasedRunner(...)
# 4.注册必备 hook
runner.register_training_hooks(cfg.lr_config, optimizer_config,
cfg.checkpoint_config, cfg.log_config,
cfg.get('momentum_config', None))
# 5.如果需要 val,则还需要注册 EvalHook
runner.register_hook(eval_hook(val_dataloader, **eval_cfg))
# 6.注册用户自定义 hook
runner.register_hook(hook, priority=priority)
# 7.权重恢复和加载
if cfg.resume_from:
runner.resume(cfg.resume_from)
elif cfg.load_from:
runner.load_checkpoint(cfg.load_from)
# 8.运行,开始训练
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)上面的流程比较简单,一般大家比较难以理解的是 runner.run
内部逻辑,下小节进行详细分析,而对于测试逻辑由于比较简单,就不详细描述了,简单来说测试流程下不需要
runner,直接加载训练好的权重,然后进行 model 推理即可。
3.2 Runner 训练和验证代码抽象
runner 对象内部的 run 方式是一个通用方法,可以运行任何 workflow,目前常用的主要是 train 和 val。
- 当配置为:workflow = [('train', 1)],表示仅仅进行 train workflow,也就是迭代训练
- 当配置为:workflow = [('train', n),('val', 1)],表示先进行 n 个 epoch 的训练,然后再进行1个 epoch 的验证,然后循环往复,如果写成 [('val', 1),('train', n)] 表示先进行验证,然后才开始训练
当进入对应的 workflow,则会调用 runner 里面的 train() 或者 val(),表示进行一次 epoch 迭代。其代码也非常简单,如下所示:
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self.call_hook('before_train_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True)
self.call_hook('after_train_iter')
self.call_hook('after_train_epoch')
def val(self, data_loader, **kwargs):
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
self.call_hook('before_val_epoch')
for i, data_batch in enumerate(self.data_loader):
self.call_hook('before_val_iter')
with torch.no_grad():
self.run_iter(data_batch, train_mode=False)
self.call_hook('after_val_iter')
self.call_hook('after_val_epoch')核心函数实际上是 self.run_iter(),如下:
def run_iter(self, data_batch, train_mode, **kwargs):
if train_mode:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.train_step(data_batch,...)
else:
# 对于每次迭代,最终是调用如下函数
outputs = self.model.val_step(data_batch,...)
if 'log_vars' in outputs:
self.log_buffer.update(outputs['log_vars'],...)
self.outputs = outputs上述 self.call_hook() 表示在不同生命周期调用所有已经注册进去的 hook,而字符串参数表示对应的生命周期。以 OptimizerHook 为例,其执行反向传播、梯度裁剪和参数更新等核心训练功能:
@HOOKS.register_module()
class OptimizerHook(Hook):
def __init__(self, grad_clip=None):
self.grad_clip = grad_clip
def after_train_iter(self, runner):
runner.optimizer.zero_grad()
runner.outputs['loss'].backward()
if self.grad_clip is not None:
grad_norm = self.clip_grads(runner.model.parameters())
runner.optimizer.step()可以发现 OptimizerHook 注册到的生命周期是 after_train_iter,故在每次 train() 里面运行到
self.call_hook('aftertrainiter')
时候就会被调用,其他 hook 也是同样运行逻辑。
3.3 Model 训练和测试代码抽象
前面说个,训练和验证的时候实际上调用了 model 内部的
train_step 和 val_step
函数,理解了两个函数调用流程就理解了 MMDetection
训练和测试流程。
注意,由于 model 对象会被 DataParallel 类包裹,故实际上此时的 model,是指的 MMDataParallel 或者 MMDistributedDataParallel。以非分布式 train_step 流程为例,其内部完成调用流程图示如下:

3.3.1 train 或者 val 流程
(1) 调用 runner 中的 train_step 或者
val_step
在 runner 中调用 train_step 或者
val_step,代码如下:
#=================== mmcv/runner/epoch_based_runner.py ==================
if train_mode:
outputs = self.model.train_step(data_batch,...)
else:
outputs = self.model.val_step(data_batch,...)实际上,首先会调用 DataParallel 中的 train_step 或者
val_step ,其具体调用流程为:
# 非分布式训练
#=================== mmcv/parallel/data_parallel.py/MMDataParallel ==================
def train_step(self, *inputs, **kwargs):
if not self.device_ids:
inputs, kwargs = self.scatter(inputs, kwargs, [-1])
# 此时才是调用 model 本身的 train_step
return self.module.train_step(*inputs, **kwargs)
# 单 gpu 模式
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 此时才是调用 model 本身的 train_step
return self.module.train_step(*inputs[0], **kwargs[0])
# val_step 也是的一样逻辑
def val_step(self, *inputs, **kwargs):
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 此时才是调用 model 本身的 val_step
return self.module.val_step(*inputs[0], **kwargs[0])可以发现,在调用 model 本身的 train_step 前,需要额外调用 scatter 函数,前面说过该函数的作用是处理 DataContainer 格式数据,使其能够组成 batch,否则程序会报错。
如果是分布式训练,则调用的实际上是
mmcv/parallel/distributed.py/MMDistributedDataParallel,最终调用的依然是
model 本身的 train_step 或者 val_step。
(2) 调用 model 中的 train_step 或者
val_step
其核心代码如下:
#=================== mmdet/models/detectors/base.py/BaseDetector ==================
def train_step(self, data, optimizer):
# 调用本类自身的 forward 方法
losses = self(**data)
# 解析 loss
loss, log_vars = self._parse_losses(losses)
# 返回字典对象
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
def forward(self, img, img_metas, return_loss=True, **kwargs):
if return_loss:
# 训练模式
return self.forward_train(img, img_metas, **kwargs)
else:
# 测试模式
return self.forward_test(img, img_metas, **kwargs)forward_train 和 forward_test
需要在不同的算法子类中实现,输出是 Loss 或者 预测结果。
(3) 调用子类中的 forward_train 方法
目前提供了两个具体子类,TwoStageDetector 和
SingleStageDetector ,用于实现 two-stage 和 single-stage
算法。
对于 TwoStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/two_stage.py/TwoStageDetector ============
def forward_train(...):
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
losses = dict()
# RPN forward and loss
if self.with_rpn:
# 训练 RPN
proposal_cfg = self.train_cfg.get('rpn_proposal',
self.test_cfg.rpn)
# 主要是调用 rpn_head 内部的 forward_train 方法
rpn_losses, proposal_list = self.rpn_head.forward_train(x,...)
losses.update(rpn_losses)
else:
proposal_list = proposals
# 第二阶段,主要是调用 roi_head 内部的 forward_train 方法
roi_losses = self.roi_head.forward_train(x, ...)
losses.update(roi_losses)
return losses对于 SingleStageDetector 而言,其核心逻辑是:
#============= mmdet/models/detectors/single_stage.py/SingleStageDetector ============
def forward_train(...):
super(SingleStageDetector, self).forward_train(img, img_metas)
# 先进行 backbone+neck 的特征提取
x = self.extract_feat(img)
# 主要是调用 bbox_head 内部的 forward_train 方法
losses = self.bbox_head.forward_train(x, ...)
return losses3.3.2 test流程
由于没有 runner 对象,测试流程简单很多,下面简要概述:
调用 MMDataParallel 或 MMDistributedDataParallel 中的
forward方法调用 base.py 中的
forward方法调用 base.py 中的
self.forward_test方法如果是单尺度测试,则会调用 TwoStageDetector 或 SingleStageDetector 中的
simple_test方法,如果是多尺度测试,则调用aug_test方法最终调用的是每个具体算法 Head 模块的
simple_test或者aug_test方法
四、 总结
本文基于第一篇解读文章,详细地从三个层面全面解读了 MMDetection 框架,希望读者读完本文,能够对 MMDetection 框架设计思想、组件间关系和整体代码实现流程了然于心。