
mmdetection3d
MMDetection3D 整体框架介
[TOC]
一、前言
由于3D本身数据的复杂性和MMDetection3D支持任务(电云D检测、单目3D检测、多模态3D检测和点云3D语义分割等)和场景(室内和外)的多样性,整个框架结构相对复杂,门槛高,这里对MMDetection3D整个框架进行整体的了解,包括设计流程,核心组件,数据集处理方法等。
整个框架的代码库目录结构如下:
# MMDetection3D 代码目录结构,展示主要部分
mmdetection3d
|
|- configs # 配置文件
|- data # 原始数据及预处理后数据文件
|- mmdet3d
| |- ops # cuda 算子(即将迁移到 mmcv 中)
| |- core # 核心组件
| |- datasets # 数据集相关代码
| |- models # 模型相关代码
| |- utils # 辅助工具
| |- ...
|- tools
| |- analysis_tools # 分析工具,包括可视化、计算flops等
| |- data_converter # 各个数据集预处理转换脚本
| |- create_data.py # 数据预处理入口
| |- train.py # 训练脚本
| |- test.py # 测试脚本
| |- ...
|- ... 二、任务介绍
3D 目标检测按照输入数据模态划分可以分为:点云 3D 检测、纯视觉 3D 检测以及多模态 3D 检测(点云+图片)。



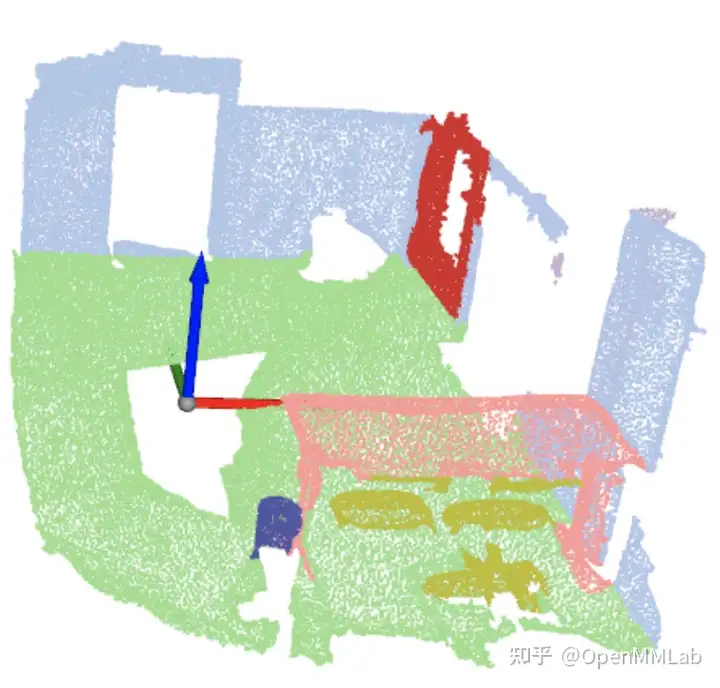
除此之外,MMDetection3D还拓展到了点云3D语义分割领域,目前已经支持了室内点云语义分割,同时会在将来支持室外点云语义分割。
三、算法模型支持
所有模型相关代码位于mmdet3d/models下,MMDetection3D支持的各个方向的模型大体可以归类如下:

总体来说,由于MMDetection3D依赖于MMDetection和MMSegmentation,所以很多的模型及组件都是直接复用或继承而来。目前在MMDetection3D内,整体模型的构建方式会根据任务类型被划分为三种方式,具体如下:
点云3D检测(包含多模态3D检测):

对于点云3D检测(多模态3D检测),我们继承自MMDetection中的BaseDetector构建了适用于3D检测的Base3DDetector,再根据检测中的单价段和二阶段分别构造,需要注意的是不同于SingleStage3DDetector,为了尽可能的复用已有的代码组件,二阶段检测器TwoStage3DDetector同时继承自Base3DDetector和TwoStageDetector,图中只列出了部分支持的模型算法。
单目3D检测:

对于单目3D检测,考虑到和2D检测输入数据的一致性,同事方便做2D检测的同学可以快速上手单目3D检测,我们继承自MMDetection中的SingleStageDetector构建了SingleStageMono3DDetector,目前所支持的单目3D检测算法都是基于该类构建的。
点云3D语义分割:

对于点云 3D 语义分割,我们继承自 MMSegmentation 中的
BaseSegmentor 构建了适用于点云分割的
Base3DSegmentor,而目前所支持的点云分割算法都是遵循
EncoderDecoder3D 模式。
四、数据预处理
该部分对应于toos/create_data.py,各个数据集预处理脚本位于tools/data_converter目录下。由于3D数据集的多样性,MMDetection3D会对数据集做预处理。这里,我们从整体视角来看下数据预处理的文件生成过程:

在MMDetection3D中,不同的任务和不同的场景(室内、外)的数据预处理都会存在一定的区别,如上图所示,会产生不同的预处理后的文件,便于后续训练。
对所有的任务和场景,统一用数据处理脚本转换后的pkl文件,该文件包含数据集的各种信息,包括数据集路径、calib信息和标注信息等,从而做到各个数据集内部格式尽可能的统一。
对于点云(多模态)3D检测,室内和室外数据集生成的文件是不一样的:
对于某些室外数据集,我们会借助pkl文件的信息进一步提取reduced_point_cloud和gt_database:前者是仅包含前方视野的点云文件,通常存在于kitti数据集处理过程中,因为kitti数据集仅包含前方视野的标注;后者则是包含在训练集数据集的每个3D边界框中的点云数据分别提取出来得到的各个物体的点云文件,常用来在数据增强时使用(copy-paster)。
对于室内数据集,由于点云较为密集,通常会进行点云的下采用处理,保存在points内。
对于单目3D检测,整个模型构建的流程是遵循2D检测的,同样的在数据处理的过程中,在生成基本的pkl文件后,还需要将其抓换位coco标注格式的json文件,该过程中会对pkl的标注信息做相应处理,实际在该任务中,pkl文件用来提供data信息,json文件提供标注信息。
对于点云3D语义分割,目前MMDetection3D仅支持室内点云分割,相对于检测任务,如图所示需要生成额外的文件:instance_mask 包含每个点云的实例标签,semantic_mask包含每个点云的语义标签,seg_info包含额外的辅助训练的信息。
五、模块抽象
和MMDetection一脉相承,整个MMDetection3D的模块内部抽象流程也主要包括Pipeline、DataParallel、Model、Runner和Hooks。
5.1Pipeline
具体在Pipeline方面由于数据模态的不同,所以在数据处理过程中包含不同的信息。
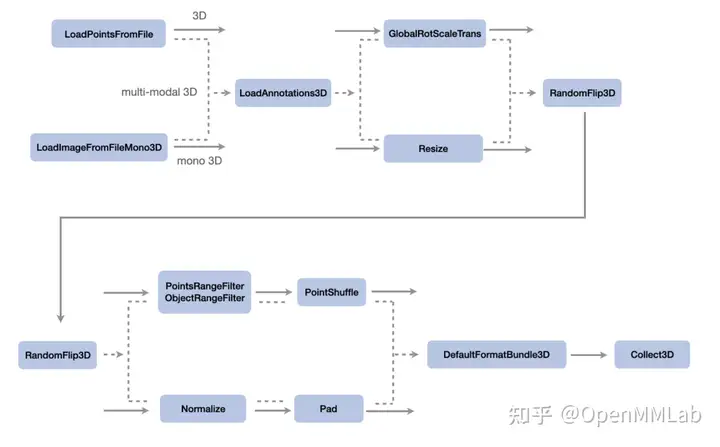
上图展示了三个比较典型的3D检测Pipeline,流程自上而下分别是点云3D检测、多模态3D检测和单目3D检测,从上述的流程可以看出,pipeline其实是由一系列的按照插入顺序插入顺序进行的数据处理模块组成。MMDetection3D
对于点云 3D 检测提供了很多常用的 pipeline
模块,比如GlobalRotScaleTrans(点云的旋转缩放)、PointsRangeFilter /
ObjectRangeFilter(限定了点云和物体的范围)、PointShuffle(打乱点云数据);而对于单目
3D 检测基本就是直接调用 MMDetection 的数据处理模块,比如 Resize
(图片缩放)、Normalize (正则化)、Pad
(图片填充);多模态检测则兼用两者。我们可以看到其实这些任务共享了部分的
pipeline 模块,比如 LoadAnnotations3D
(标签载入)、RandomFlip3D(会对点云和图片同时进行翻转)、DefaultFormatBundle3D(数据格式化)、Collect3D
(选取需要用于训练的数据和标签),这些代码都在
mmdet3d/datasets/pipeline 目录下。
5.2 Model
在该部分我们按照任务类型分类,对于整个模型内部做抽象介绍。和2D检测类型,3D检测器通常也包含了几个核心组件:Backbone用于提取特征、Neck进行特征融合和增强、Head用于输出需要的结果。
- 点云3D检测模型
目前云目标检测按照对点云数据的处理方式,可以分为体素处理方法 (Voxel-based) 和原始点云处理方法 (Point-based),这两种方法其实在构建模型的时候会有一定的区别,整体的模型构建按照下图流程所示:
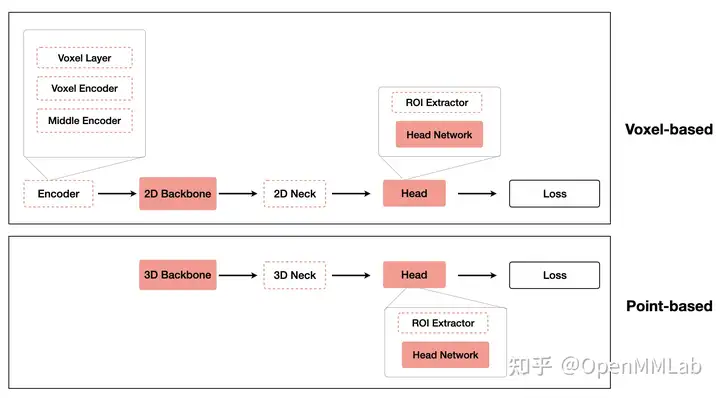
基于体素的模型通常需要
Encoder来对点云体素化,如HardVFE和PointPillarScatter等,采用的稀疏卷积或者 Pillars 的方法从点云中生成 2D 特征图,然后基本可以套用 2D 检测流程进行 3D 检测。基于原始点云模型通常直接采用 3D Backbone (Pointnet / Pointnet++ 等) 提取点的特征,再针对提取到的点云特征采用 RoI 或者 Group 等方式回归 3D bounding box。有关的具体内容我们会在后续的文章中针对典型的方法进行分析介绍.
- 单目3D检测模型
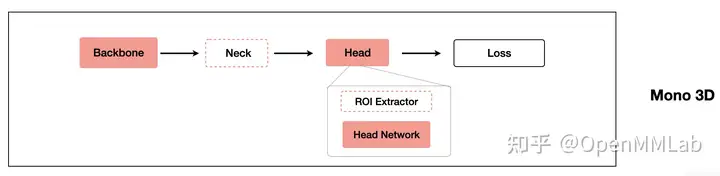
由于单目 3D 检测的输入是图片,输出是 3D bounding box, 所以整体的检测流程和模型组成来说基本和 2D 检测保持一致。
- 多模态3D检测模型
多模态的检测模型从组成来看可以看成2D检测模型和点云检测模型的拼接。
- 点云3D语义分割模型

MMDetection3D 内部支持的 3D 分割模型都是符合
EncoderDecoder 结构的,需要 backbone 来 encode
feature, decode_head
用来预测每个点云的类别的进行分割,目前主要只支持室内场景的 3D
语义分割。
六、训练和测试流程
首先我们训练和验证调用的是 tools/train.py 脚本,先进行
Dataset、Model 等相关类初始化,然后我们构建了一个
runner,最终模型的训练和验证过程是发生在 runner
内部的,而训练和验证的时候实际上是 runner 调用了 model 内部的
train_step 和 val_step 函数。
6.1train和val流程
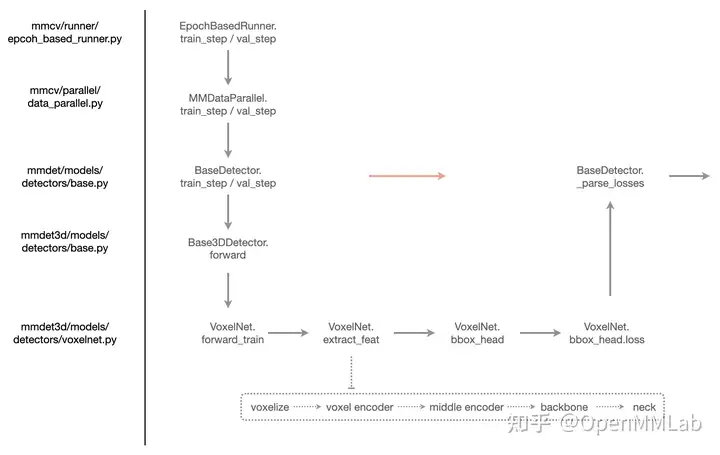
(1) 调用 runner 中的 train_step 或者
val_step
在 runner 中调用 train_step 或者
val_step,代码如下:
#=================== mmcv/runner/epoch_based_runner.py ==================
if train_mode:
outputs = self.model.train_step(data_batch,...)
else:
outputs = self.model.val_step(data_batch,...) 实际上,首先会调用 DataParallel 中的 train_step 或者
val_step ,其具体调用流程为:
# 非分布式训练
#=================== mmcv/parallel/data_parallel.py/MMDataParallel ==================
def train_step(self, *inputs, **kwargs):
if not self.device_ids:
inputs, kwargs = self.scatter(inputs, kwargs, [-1])
# 此时才是调用 model 本身的 train_step
return self.module.train_step(*inputs, **kwargs)
# 单 gpu 模式
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 此时才是调用 model 本身的 train_step
return self.module.train_step(*inputs[0], **kwargs[0])
# val_step 也是的一样逻辑
def val_step(self, *inputs, **kwargs):
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
# 此时才是调用 model 本身的 val_step
return self.module.val_step(*inputs[0], **kwargs[0]) 可以发现,在调用 model 本身的 train_step 前,需要额外调用 scatter 函数,前面说过该函数的作用是处理 DataContainer 格式数据,使其能够组成 batch,否则程序会报错。
如果是分布式训练,则调用的实际上是
mmcv/parallel/distributed.py/MMDistributedDataParallel,最终调用的依然是
model 本身的 train_step 或者 val_step。
(2) 调用 model 中的 train_step 或者
val_step
训练流程:
#=================== mmdet/models/detectors/base.py/BaseDetector =============
def train_step(self, data, optimizer):
# 调用本类自身的 forward 方法
losses = self(**data)
# 解析 loss
loss, log_vars = self._parse_losses(losses)
# 返回字典对象
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img_metas']))
return outputs
#=================== mmdet/models/detectors/base.py/Base3DDetector ===========
# Base3DDetector 主要是重写了 forward,改变了模型输入数据的类型,可同时传入点云数据和图片数据,从而满足多模态检测的需求
@auto_fp16(apply_to=('img', 'points'))
def forward(self, return_loss=True, **kwargs):
if return_loss:
# 训练模式
return self.forward_train(**kwargs)
else:
# 测试模式
return self.forward_test(**kwargs) forward_train 和 forward_test
需要在不同的算法子类中实现,输出是 Loss 或者 预测结果。
(3) 调用子类中的 forward_train 方法
PointPillars 采用的是 VoxelNet 检测器,核心逻辑还是比较通用的。
#============= mmdet/models/detectors/voxelnet.py/VoxelNet ============
def forward_train(self,
points,
img_metas,
gt_bboxes_3d,
gt_labels_3d,
gt_bboxes_ignore=None):
# 先进行点云的特征提取
x = self.extract_feat(points, img_metas)
# 主要是调用 bbox_head 内部的 forward_train 方法,得到 head 输出
outs = self.bbox_head(x)
loss_inputs = outs + (gt_bboxes_3d, gt_labels_3d, img_metas)
# 将 head 部分的输出和数据的 label 送入计算 loss
losses = self.bbox_head.loss(
*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
return losses (4) 调用 model 中的 _parse_losses
方法
#=================== mmdet/models/detectors/base.py/BaseDetector ==================
def _parse_losses(self, losses):
# 返回来的 losses 是一个dict, 我们需要对 loss 进行求和
log_vars = OrderedDict()
for loss_name, loss_value in losses.items():
if isinstance(loss_value, torch.Tensor):
log_vars[loss_name] = loss_value.mean()
elif isinstance(loss_value, list):
log_vars[loss_name] = sum(_loss.mean() for _loss in loss_value)
else:
raise TypeError(
f'{loss_name} is not a tensor or list of tensors')
loss = sum(_value for _key, _value in log_vars.items()
if 'loss' in _key)
log_vars['loss'] = loss
for loss_name, loss_value in log_vars.items():
# reduce loss when distributed training
if dist.is_available() and dist.is_initialized():
loss_value = loss_value.data.clone()
dist.all_reduce(loss_value.div_(dist.get_world_size()))
log_vars[loss_name] = loss_value.item()
return loss, log_vars 6.2 test流程
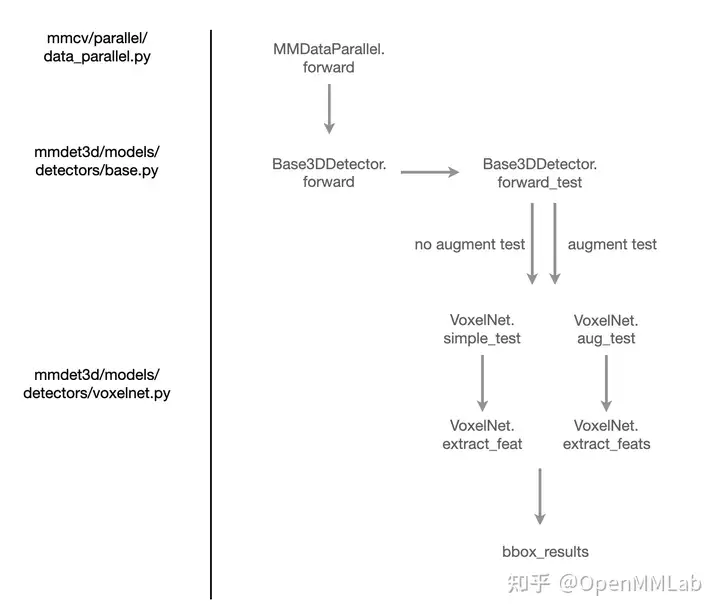
test 流程如上图所示, 我们可以看见在 test 的时候流程相比 train / val 更为简单,没有调用 runner 对象。
(1) 调用 model 中的 forward_test
#=================== mmdet/models/detectors/base.py/Base3DDetector ===========
def forward_test(self, points, img_metas, img=None, **kwargs):
num_augs = len(points)
if num_augs != len(img_metas):
raise ValueError(
'num of augmentations ({}) != num of image meta ({})'.format(
len(points), len(img_metas)))
# 根据 points list 长度判断是 simple_test 还是 aug_test
if num_augs == 1:
img = [img] if img is None else img
return self.simple_test(points[0], img_metas[0], img[0], **kwargs)
else:
return self.aug_test(points, img_metas, img, **kwargs)
(2) 调用子类 的 simple_test 或
aug_test
#============= mmdet/models/detectors/voxelnet.py/VoxelNet ============
def simple_test(self, points, img_metas, imgs=None, rescale=False):
# 无数据增强测试
# 提取特征
x = self.extract_feat(points, img_metas)
# 调用 head
outs = self.bbox_head(x)
# 根据 head 输出结果生成 bboxes
bbox_list = self.bbox_head.get_bboxes(
*outs, img_metas, rescale=rescale)
# 对检测结果进行格式调整
bbox_results = [
bbox3d2result(bboxes, scores, labels)
for bboxes, scores, labels in bbox_list
]
return bbox_results
def aug_test(self, points, img_metas, imgs=None, rescale=False):
# 数据增强测试
feats = self.extract_feats(points, img_metas)
# 目前只支持单个 sample 的 aug_test
aug_bboxes = []
for x, img_meta in zip(feats, img_metas):
outs = self.bbox_head(x)
bbox_list = self.bbox_head.get_bboxes(
*outs, img_meta, rescale=rescale)
bbox_list = [
dict(boxes_3d=bboxes, scores_3d=scores, labels_3d=labels)
for bboxes, scores, labels in bbox_list
]
aug_bboxes.append(bbox_list[0])
# 将增强后的 bboxes 进行 merge 合并操作
merged_bboxes = merge_aug_bboxes_3d(aug_bboxes, img_metas,
self.bbox_head.test_cfg)
return [merged_bboxes]
以上我们主要分析了整体的框架流程。