
PETR
PETR初学习
前言
当前基于BEV的纯视觉3D检测中,划分的方式有很多,按照单目、环视、视觉+Lidar的融合等等。然后,从2D到3D的投影方式也有不同方式来划分,比如IPM方式、Lifg-Splat、MLP、Transformer等。
目前主流的方法中,按照BEV特征的构建方式来划分,主要可以分为两大方向:
- 1、LSS框架,例如BEVDet等采用2D向3D的投影方式,先Lift->再Splat;
- 2、BEVFormer和DETR3D的框架,采用3D空间点向2D空间查询的方式。
而PETR提出了一种新的2D和3D的融合方式,也可以另算第三种方法,其不是简单的2D到3D投影,也不是3D到2D的查询,是直接将3D位置空间变换成和2D特征相同尺度的特征,然后将2D和3D特征融合后得到新的特征。
关于DETR和PETR3D的网络框架:
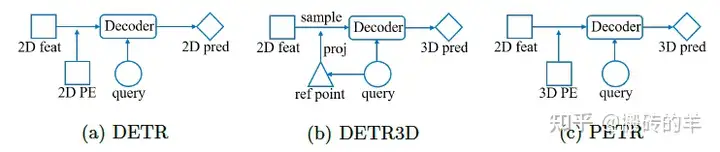
- DETR框架,单图片2D目标检测,首先采用CNN网络提取图片特征,然后加入2D position encoding,送入到transformer decoder结构中预测2D目标位置和类别;
- DETR3D,multi-view环视图像的3D目标检测任务,对所有环视的图像提取2D特征,增加一个预测网络,利用这个预测网络,将query输入到该网络结构生成ref point(可以理解为粗略的3D坐标位置),通过ref point+相机内参,转换到2D图像坐标中,去2D特征中去查询对应的位置的特征,并利用deformable做Sampler,采样后的特征用来更新query,利用更新的query送入后面transformer decoder结构中来预测3D目标;
- PETR框架,也是multi-view环视图像的3D目标检测任务,首先也是对所以的环视图像提取2D特征,每个相机的特征对应有自己的3D位置编码,然后将2D特征和3D位置编码融合,送入后面的transformer decoder结构中预测3D目标。
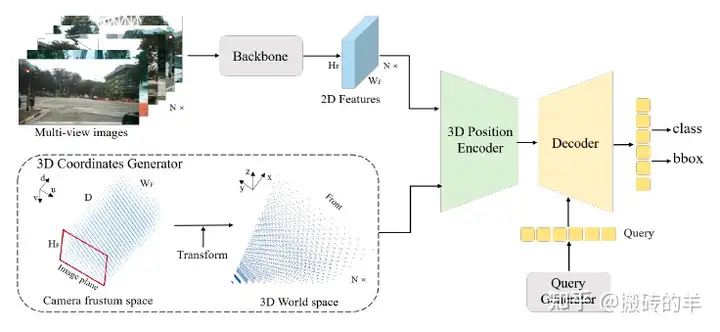
一、方法介绍
1.1、3D坐标生成
PETR中多视角下的图像特征提取与DETR3D区别不大,采用CNN网络对环视图像进行2D特征提取。而创新点在于3D Coordinates Generator的生成。

最后,根据给定的空间范围
1.2 3D Position Encoder

经过Backbone得到的2D图像特征: 3D Position Embedding,再和
为了说明3D
PE的作用,作者从前视图像中随机挑选了3个像素点对应的PE,并计算这3个PE和其他所有视角图像PE的相似度,如下图所示。3D世界空间中左前方的一点理论上会同时出现在前视相机左侧和左前相机右侧,从第一行图像可以看出,PE相似度的确是符合这个先验认知的。所以可以证明3D
PE的确建立了3D空间中不同视角的位置关联。 
1.3 Query Generator
DETR使用一组可学习的参数作为初始的object query,DETR3D基于初始的object query预测一组参考点,PETR为了降低3D场景的收敛难度,首先在3D世界空间中以均匀分布的方式初始化一组可学习的3D锚点,然后锚点经过一个小型MLP生成初始的object query。论文作者还提到,如果使用DETR的方式或在BEV空间生成锚点,最终模型性能都不理想。
1.4 Decoder、Head and Loss
PETR网络的后半部分基本就沿用DETR和DETR3D的配置:使用 L L L个标准Transformer Decoder层迭代地更新object query;检测头和回归头都沿用DETR3D,回归目标中心相对于锚点的偏移量;分类使用focal loss,3D框回归使用L1 loss。
1.5 可视化结果
