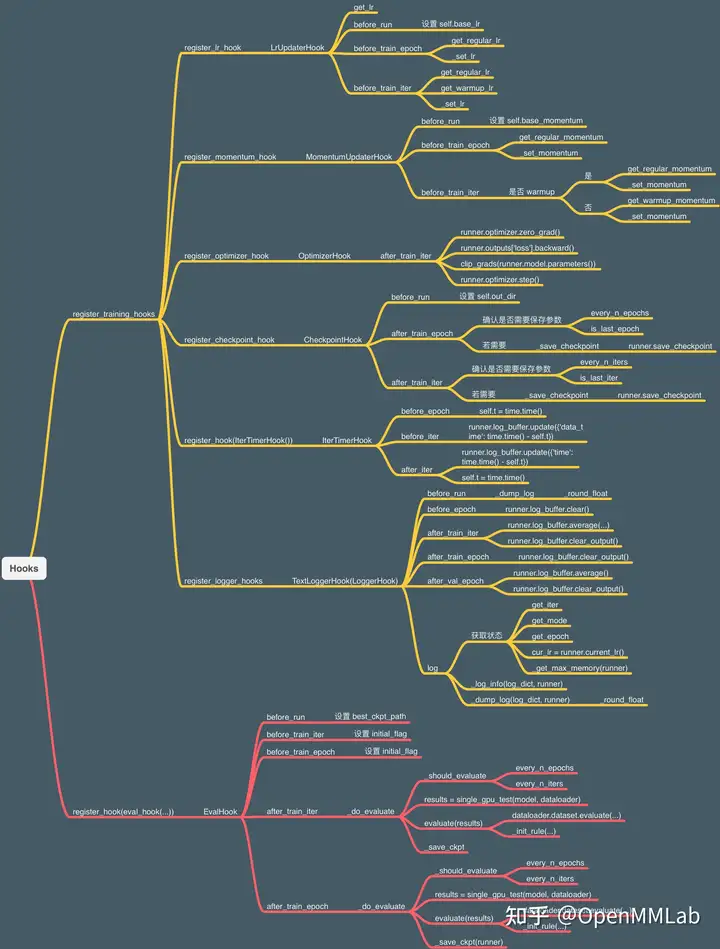
runner与hook
Runner和Hook详细解析
1.Runner和Hook概述
Runner又称执行器,负责模型训练过程的调度,主要目的是让用户使用更少的代码以及灵活可配置的方式开启训练。换句话说,MMCV将整个训练过程封装起来了,并使用Runner进行管理和配置。高度封装虽然减少了代码量,但如何对内部流程进行自定义的修改(比如动态调整学习率等)?这时就需要用到Hook机制。
Hook是能够改变程序执行流程的一种技术统称。通俗的说,Hook可以理解为一种触发器,在程序预定义的位置执行预定义的函数。MMCV已经在几个常用的位置预留了接口函数(称为回调函数),如下图所示。MMCV已经实现了一些常用的Hook函数,同时用户也可以增加自己的Hook函数,非常方便。当程序执行到指定位置时,就会进入到回调函数中,执行相应的功能,执行结束后再接着执行主流程。

上图对应到具体的代码:
# 开始运行时调用
before_run()
while self.epoch < self._max_epochs:
# 开始 epoch 迭代前调用
before_train_epoch()
for i, data_batch in enumerate(self.data_loader):
# 开始 iter 迭代前调用
before_train_iter()
self.model.train_step()
# 经过一次迭代后调用
after_train_iter()
# 经过一个 epoch 迭代后调用
after_train_epoch()
# 运行完成前调用
after_run()总的来说,Runner封装了OpenMMLab体系下各个框架的训练和验证流程,负责管理训练/验证过程的整个生命周期;通过预定义的回调函数,用户可以插入定制化Hook,实现各种各样定制化的需求。 ## 2.Runner类
Runner分为EpochBasedRunner和IterBasedRunner,顾名思义,前者以epoch的方式管理流程,后者以iter的方式管理流程,它们都是BaseRunner的子类。BaseRunner的任何子类都需要实现run()、train()、val()和save_checkpoint()四个方法,这也是Runner的核心方法。这里以EpochBasedRunner为例对上述四个函数进行分析,为了使代码结构看起来更清晰,删去了和核心功能无关的代码。hook 的本质是回调函数,也就是在特定时刻会调用被提前注册好的函数。文章中说的拦截功能大体意思是说触发函数调用,具体实现方式其实没有限制,可以直接通过函数实现,也可以通过装饰器实现
2.1 构造函数
EpochBasedRunner和IterBasedRunner都是BaseRunner的子类,继承了BaseRunner的构造函数。runner默认调用model类中的train_step()和val_step()进行训练和验证,如果指定了batch_processor,则会调用batch_processor对data_loader中的数据进行处理。
class BaseRunner(metaclass=ABCMeta):
def __init__(self,
model, # [torch.nn.Module] 要运行的模型
batch_processor=None, # 过时用法, 通过实现模型中的train_step()和val_step()方法替代
optimizer=None, # [torch.optim.Optimizer] 优化器, 可以是一个也可以是一组通过dict配置的优化器
work_dir=None, # [str] 保存检查点和Log的目录
logger=None, # [logging.Logger] 训练中使用的日志记录器
meta=None, # [dict] 一些信息, 这些信息会在logger hook中记录
max_iters=None, # [int] 训练epoch数
max_epochs=None): # [int] 训练迭代次数2.2 run()函数
run()是runner类的主调函数,会根据workflow指定的工作流,对data_loaders中的数据进行处理。目前MMCV支持训练和验证两种工作流,对于EpochBasedRunner而言,workflow配置为[('train', 2),('val', 1)]表示先训练2个epoch,然后验证一个epoch;[('train', 1)]表示只进行训练,不进行验证。如果是IterBasedRunner,[('train', 2),('val', 1)]则表示先训练2个iter,然后验证一个iter。
def run(self, data_loaders, workflow, max_epochs=None, **kwargs):
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
# 根据工作流确定当前是运行train()还是val(), getattr返回对应的函数句柄
epoch_runner = getattr(self, mode)
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
# 运行train()或val()
epoch_runner(data_loaders[i], **kwargs)2.3 train()和val()函数
train()和val()函数循环调用run_iter()完成一个epoch流程。函数开头的self.model.train()和self.model.eval()实际上调用的是torch.nn.module.Module的成员函数,将当前模块设置为训练模式或验证模式,两种不同模式下batchnorm、dropout等层的操作会有区别。然后由于测试过程不需要梯度回传,所以val函数加了一个装饰器@torch.no_grad()。
def train(self, data_loader, **kwargs):
# 将模块设置为训练模式
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
for i, data_batch in enumerate(self.data_loader):
self.run_iter(data_batch, train_mode=True, **kwargs)
self._iter += 1
self._epoch += 1
@torch.no_grad()
def val(self, data_loader, **kwargs):
# 将模块设置为验证模式
self.model.eval()
self.mode = 'val'
self.data_loader = data_loader
for i, data_batch in enumerate(self.data_loader):
self.run_iter(data_batch, train_mode=False)train()和val()的核心函数是run_iter(),根据train_mode参数调用model.train_step()或model.val_step(),这两个函数最终会执行我们自己模型的forward()函数,返回loss值.
def run_iter(self, data_batch, train_mode, **kwargs):
if self.batch_processor is not None:
outputs = self.batch_processor(self.model, data_batch, train_mode=train_mode, **kwargs)
elif train_mode:
outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)
else:
outputs = self.model.val_step(data_batch, self.optimizer, **kwargs)
self.outputs = outputs2.4 save_checkpoint()函数
save_checkpoint()函数调用torch.save将检查点以下列格式保存。
checkpoint = {
'meta': dict(), # 环境信息(比如epoch_num, iter_num)
'state_dict': dict(), # 模型的state_dict()
'optimizer': dict()) # 优化器的state_dict()
}3.Hook类
MMCV在./mmcv/runner/hooks/hook.py中定义了Hook的基类以及Hook的注册器HOOKS。作为基类,Hook本身没有实现具体的函数,只是提供了before_run、after_run等6个接口函数,其他所有的Hooks都通过继承Hook类并重写相应的函数完整指定功能。
from mmcv.utils import Registry
HOOKS = Registry('hook')
class Hook: def before_run(self, runner): pass
def after_run(self, runner): pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
passMMCV已经实现了部分常用的Hooks,如下图所示。默认Hook不需要用户自行注册,通过配置文件配置对应的参数即可;定制Hook则需要用户手动注册进去。
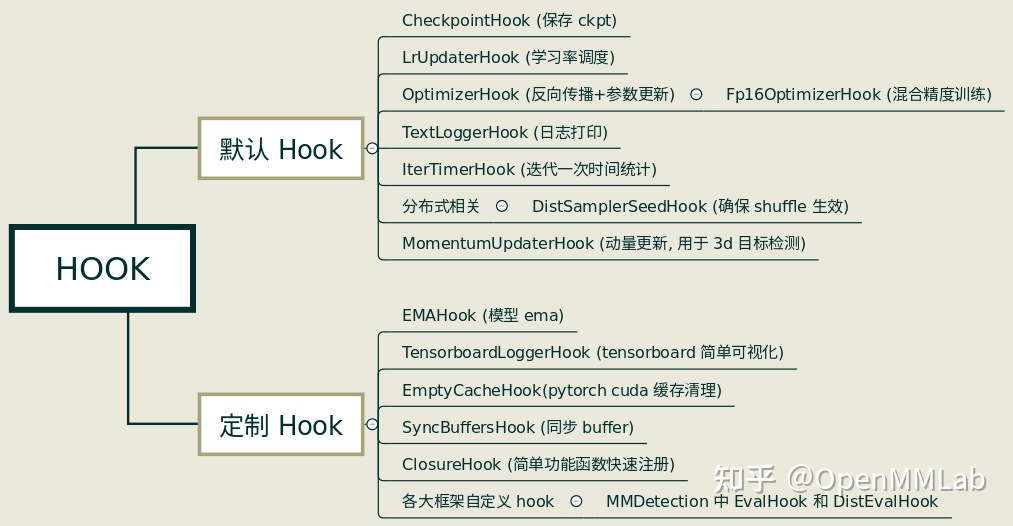
Hook也是一个模块,使用时需要定义、注册、调用3个步骤。
3.1 定义
MMCV实现的Hook都在./mmcv/runner/hooks目录下,这里以CheckpointHook为例介绍一下怎么新建一个Hook。
首先从hook.py中导入注册器HOOKS以及基类Hook。然后新建一个名为CheckpointHook类继承Hook基类,由于Hook基类没有定义构造函数,这里首先必须自己定义__init__函数,然后根据Hook需要实现的功能,重写Hook基类中的一种或几种方法。比如MMCV会在每次训练开始前打印checkpoint的保存路径,会在每次循环结束后或每个epoch执行完成后保存checkpoint,因此CheckpointHook类重写了before_run、after_train_iter和after_train_epoch这3个方法。
from .hook import HOOKS, Hook
@HOOKS.register_module()
class CheckpointHook(Hook):
def __init__(self,
interval=-1,
by_epoch=True,
save_optimizer=True,
out_dir=None,
max_keep_ckpts=-1,
save_last=True,
sync_buffer=False,
file_client_args=None,
**kwargs):
...
def before_run(self, runner):
...
def after_train_iter(self, runner):
...
def after_train_epoch(self, runner):
...3.2 注册
对于MMCV的默认Hook,在执行runner.run()前会调用BaseRunner类中的register_training_hooks方法进行注册:
def register_training_hooks(self,
lr_config,
optimizer_config=None,
checkpoint_config=None,
log_config=None,
momentum_config=None,
timer_config=dict(type='IterTimerHook'),
custom_hooks_config=None):
"""Register default and custom hooks for training.
Default and custom hooks include:
+----------------------+-------------------------+
| Hooks | Priority |
+======================+=========================+
| LrUpdaterHook | VERY_HIGH (10) |
+----------------------+-------------------------+
| MomentumUpdaterHook | HIGH (30) |
+----------------------+-------------------------+
| OptimizerStepperHook | ABOVE_NORMAL (40) |
+----------------------+-------------------------+
| CheckpointSaverHook | NORMAL (50) |
+----------------------+-------------------------+
| IterTimerHook | LOW (70) |
+----------------------+-------------------------+
| LoggerHook(s) | VERY_LOW (90) |
+----------------------+-------------------------+
| CustomHook(s) | defaults to NORMAL (50) |
+----------------------+-------------------------+
If custom hooks have same priority with default hooks, custom hooks
will be triggered after default hooks.
"""
self.register_lr_hook(lr_config)
self.register_momentum_hook(momentum_config)
self.register_optimizer_hook(optimizer_config)
self.register_checkpoint_hook(checkpoint_config)
self.register_timer_hook(timer_config)
self.register_logger_hooks(log_config)
self.register_custom_hooks(custom_hooks_config)3.3 调用
在runner执行过程中,会在特定的程序位点通过call_hook()函数调用相应的Hook。
def train(self, data_loader, **kwargs):
self.model.train()
self.mode = 'train'
self.data_loader = data_loader
self._max_iters = self._max_epochs * len(self.data_loader)
self.call_hook('before_train_epoch')
time.sleep(2) # Prevent possible deadlock during epoch transition
for i, data_batch in enumerate(self.data_loader):
self._inner_iter = i
self.call_hook('before_train_iter')
self.run_iter(data_batch, train_mode=True, **kwargs)
self.call_hook('after_train_iter')
self._iter += 1
self.call_hook('after_train_epoch')
self._epoch += 1前面调用register_hook()注册Hook的时候,会根据优先级将Hook加入到self._hooks这个列表中,在执行call_hook()时候,使用for循环就可以很简单的实现按照优先级依次调用指定的Hook了。
def call_hook(self, fn_name):
for hook in self._hooks:
getattr(hook, fn_name)(self)3.4 Hook 机制的工作流程
Hook 机制, 其实并不是 OpenMMLab 的特例,只是由于我代码经验太少,第一次见而已。 钩子编程 (hooking) ,是计算机程序设计术语,指通过拦截软件模块间的函数调用、消息传递、事件传递来修改或扩展操作系统、应用程序或其他软件组件的程序执行流程。 其中,处理被拦截的函数调用、事件、消息的代码,被称为钩子 (hook) ,应该也就是前文 AOP 编程里面的切面。
在 OpenMMLab 中,Hook 机制是由 Runner 类 (比如
IterBasedRunner, EpochBasedRunner) 和
HOOK 类 (比如 EvalHook) 配合完成的,
共同构成一套训练框架的架构规范.
首先, 在 OpenMMLab 中, 负责网络训练测试全流程的 Runner
类在训练测试周期中定义好了一系列触发器, 如下所示:
# 省略 ...
self.call_hook('before_train_epoch')
for i, data_batch in enumerate(self.data_loader):
# 省略 ...
self.call_hook('before_train_iter')
# 省略 ...
self.call_hook('after_train_iter')
# 省略 ...
self.call_hook('after_train_epoch')其次, 在与 Runner 类配合的 Hook
类及其子类中, 也定义了一堆与上面 Runner 类的触发器中
before_run, before_epoch,
before_train_iter, after_train_iter,
after_epoch, after_run
等步骤/时刻/节点同名的函数, 被称之为钩子函数,
如下所示:
class Hook:
def before_run(self, runner):
pass
def after_run(self, runner):
pass
def before_epoch(self, runner):
pass
def after_epoch(self, runner):
pass
def before_iter(self, runner):
pass
def after_iter(self, runner):
pass
# ... 省略当然, 上面这个 Hook 类是最最原始的实现, 也就是基本什么功能都没有实现.
如果想定义一些操作, 实现一些功能,可以继承这个类并定制我们需要的功能,
比如 mmcv.runner.hooks.evaluation 模块中的
EvalHook 类继承了最最原始的 Hook 类,
将里面的子函数基本都具体实现了一下; 而
mmseg.core.evaluation 模块中的 EvalHook
类则进一步继承了前一个 EvalHook 类, 重写了
after_train_iter 和 after_train_epoch
两个子函数.
有了相互配合的 Runner 类和 Hook 类之后, Runner 类实例运行到特定时刻,
就会通过触发器函数调用各个 Hook 类中的钩子函数, 从而完成特定的功能.
例如, 每个或者隔几个 after_epoch 或者
after_train_iter 触发器时刻, 可以通过 EvalHook
的 after_train_iter 函数调用 _do_evaluate
函数完成对 validation set 的 evaluation.
个人感觉, 这套 Hook 机制很像通信系统里面的轮流询问机制, 是一套在算法生命周期中规定好了种种操作的训练框架规范. 其之所以起作用,是因为在 Runner 类的被调用方法中, 每一个节点都规定了 call 相应 hook 函数的操作. Runner 类在训练过程中会依次轮流询问端口, 也就是依次 call 下每个节点的 hook 函数, 如果对应钩子函数有被专门定制过, 那就执行下该功能. 如果没有, 那就是个空函数, 直接 pass 了, 继续执行下一步,从而实现了拦截模块间的函数调用、消息传递、事件传递,从而修改或扩展组件的行为.
3.5 Hook 机制的底层实现
在清楚了 Runner 类与 Hook 类配合实现 Hook 机制的工作流程后,
还剩下的问题两个问题. 第一个问题是, 怎么让 Runner
类实例知道去调用某个具体的 Hook 类实例的子函数, 也就是怎么将 Runner
类实例和 Hook 类实例关联起来? 第二个问题是, Runner 类实例可能会调用多个
Hook 对象, 每个 Hook 对象都会有各自同名的子函数, 比如
after_train_iter, 这种情况是如何处理的?
对于第一个问题, 是通过 Runner 类的 register_hook 函数将
HOOK 类实例注册进 Runner 类实例的. 我们以 MMSegmentation
为例, 在训练模型的时候, 会调用 mmseg.apis 模块的
train_segmentor 函数. 其中有两步是给
IterBasedRunner 类实例 runner 注册 training
hooks 和 validation hooks:
runner.register_training_hooks(cfg)
runner.register_hook(eval_hook(val_dataloader, eval_cfg))Runner 类提供了两种注册 hook 的方法:
register_hook方法是直接传入一个实例化的HOOK对象,并将它插入到 Runner 类实例的self._hooks列表中;register_hook_from_cfg方法是传入一个配置项cfg,根据配置项来实例化HOOK对象, 然后再将其插入到self._hooks列表中.
其实, 第二种方法就是先调用 mmcv.build_from_cfg
方法生成一个实例化的 HOOK 对象,然后再调用第一种
register_hook 方法将实例化后的 HOOK 对象插入到
self._hooks 列表中。
有了存有注册了的 Hook 类实例的 self._hooks 列表, Runner
类在运行中调用注册了的 Hook 类实例的子函数也就顺理成章了. 看一下
BaseRunner 类中 call_hook 函数的定义, 其中
fn_name 就是
self.call_hook('after_train_iter') 传入的
after_train_iter. getattr(hook, fn_name)(self)
其实就是在调用 self._hooks 列表中的 hook 对象的名为
fn_name 的函数, 比如 EvalHook 类实例的
after_train_iter 方法. 至此, 第一个问题, 如何动态地将想要的
Hook 类实例的某个方法切入到 Runner 类实例的运行过程中已经实现了.
def call_hook(self, fn_name):
"""Call all hooks.
Args:
fn_name (str): The function name in each hook to be called, such as
"before_train_epoch".
"""
for hook in self._hooks:
getattr(hook, fn_name)(self)对于第二个问题, 从上面 call_hook 函数的定义也可以看出,
在 Runner 实例的 run 函数运行过程中, 在每一个设置
call_hook 函数的节点, 都会就轮流执行一遍
self._hooks 列表中所有 hook 实例中该时刻对应的方法. 比如,
对于 after_train_iter 这个时刻, 就是遍历一遍所有 hook
实例的 after_train_iter 方法. 如果只有一个 Hook
实例重写了该方法, 而其他实例的该方法都是 pass, 那也无所谓.
但如果有两个及以上实例的该方法实现不是 pass,
那这就涉及到一个哪个实例的方法该先被调用的问题, 具体到程序中, 则是每个
Hook 了实例被插入到 self._hooks 列表的位置的前后, 因为
call_hook 函数是依次调用的.
优先级这点, 在注册 hook 的时候就已经实现了, priority
是默认变量. 从下面 register_hook 函数的定义就可以看出,
对于新注册的一个 Hook 实例, 按照其指定的优先级, 没有指定就默认
'NORMAL' 优先级, 插入到 self._hooks 中,
优先级越高的, 越靠前. 如果新注册的 Hook 实例与就有的 Hook
实例优先级相同, 那就按照先来后到, 先来的排在更前面. 至此,
第二个问题也解决了.
def register_hook(self, hook, priority='NORMAL'):
"""Register a hook into the hook list.
The hook will be inserted into a priority queue, with the specified
priority (See :class:`Priority` for details of priorities).
For hooks with the same priority, they will be triggered in the same
order as they are registered.
Args:
hook (:obj:`Hook`): The hook to be registered.
priority (int or str or :obj:`Priority`): Hook priority.
Lower value means higher priority.
"""
assert isinstance(hook, Hook)
if hasattr(hook, 'priority'):
raise ValueError('"priority" is a reserved attribute for hooks')
priority = get_priority(priority)
hook.priority = priority
# insert the hook to a sorted list
inserted = False
for i in range(len(self._hooks) - 1, -1, -1):
if priority >= self._hooks[i].priority:
self._hooks.insert(i + 1, hook)
inserted = True
break
if not inserted:
self._hooks.insert(0, hook)3.6 示例:mmseg 中的
Hooks
在下图中,我整理了 mmseg 的 tools/train.py
整个运行周期中会用到的所有 hooks 对应的具体的 Hook
类以及相应被调用的时刻。