
PETR代码详解
PETR 代码详解
小记
看了很久的PETR源代码,后续磕盐工作以此文章为基础在上面更改,期望能顺利毕业。
本来很早就想边看边记录,但是一直以为博客的源文件没有迁移到主力本上,突然才发现上一篇4090时都迁过来了,感觉自己最近有些不在状态了,还是得开启学习记录,保持状态。
整体的代码流程
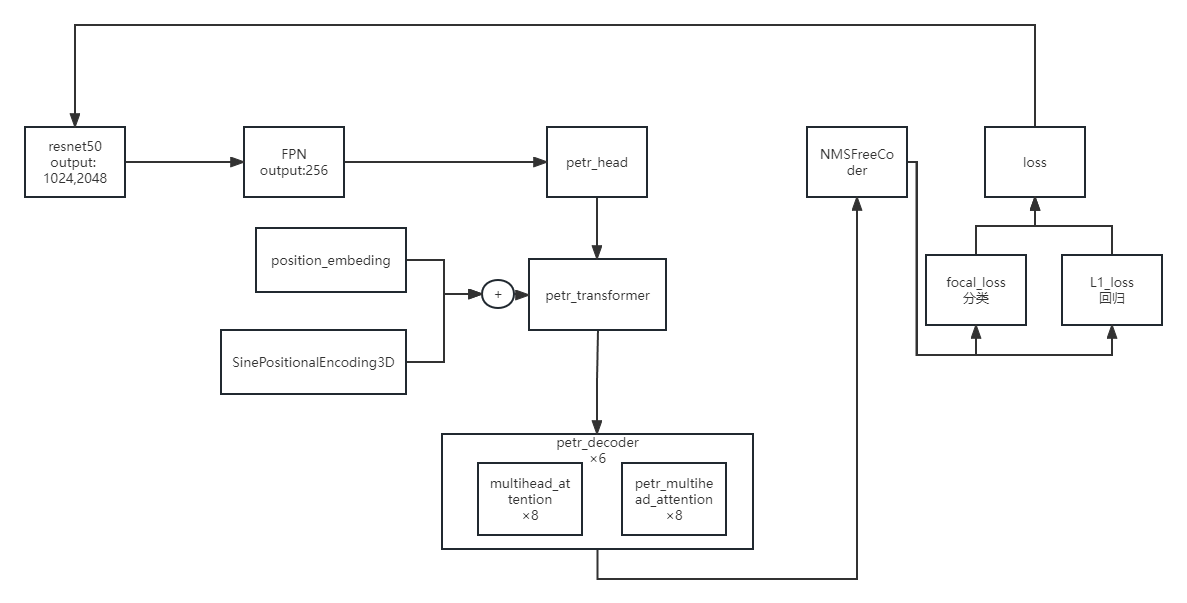
配置文件
使用了mmdet框架的代码结构,这里从头到尾把配置文件部分讲清楚,其中一些细节会同步放出定义源码讲解。
使用 petr_r50dcn_gridmask_p4.py 做解释。首先是配置加载和预先定义。
_base_ = [
'../../../mmdetection3d/configs/_base_/datasets/nus-3d.py',
'../../../mmdetection3d/configs/_base_/default_runtime.py'
]
# 这里引用了nus-3d的nuscenes数据集,所以包含了在mm3d中的配置,default_runtime是基本的runtime设置。
backbone_norm_cfg = dict(type='LN', requires_grad=True)
# LayerNorm 层归一化,设置了backbone中使用到的归一化参数
plugin=True
plugin_dir='projects/mmdet3d_plugin/'
# 给出了当前工程路径
# If point cloud range is changed, the models should also change their point
# cloud range accordingly
point_cloud_range = [-51.2, -51.2, -5.0, 51.2, 51.2, 3.0]
voxel_size = [0.2, 0.2, 8]
img_norm_cfg = dict(
mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)
# For nuScenes we usually do 10-class detection
class_names = [
'car', 'truck', 'construction_vehicle', 'bus', 'trailer', 'barrier',
'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'
]
# 十个类别
input_modality = dict(
use_lidar=False,
use_camera=True,
use_radar=False,
use_map=False,
use_external=False)
# 输入数据的模态,只使用相机图像数据模型定义部分,这一部分是重点关注部分。
model = dict(
type='Petr3D', # 首先最顶层的网络定义就是PETR,定义在PETR3d.py中,它需要多个输入参数,包括了backbone,neck,petr_head等等,属于模型的最上层定义。
use_grid_mask=True, # 一种数据增强的方法
img_backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(2, 3,), # 输出第3,4层的中间特征,维度为1024,2048,对应FPN网络
frozen_stages=-1, # -1表示不进行frozen
norm_cfg=dict(type='BN2d', requires_grad=False),
norm_eval=True,
style='caffe',
with_cp=True,
dcn=dict(type='DCNv2', deform_groups=1, fallback_on_stride=False), #加入DCNv2模块
stage_with_dcn=(False, False, True, True),
pretrained = 'ckpts/resnet50_msra-5891d200.pth',
),
# 首先是backbone,是一个resnet50,输入数据维度(B,N,3,H,W),查看源码后发现如果是5维的tensor,会将BN相乘后转换到4维输入。在模型的定义,最上层模型文件中 petr3d.py,提取特征时对输入进行了处理。
def extract_img_feat(self, img, img_metas):
"""Extract features of images."""
# print(img[0].size())
if isinstance(img, list):
img = torch.stack(img, dim=0)
B = img.size(0)
if img is not None:
input_shape = img.shape[-2:]
# update real input shape of each single img
for img_meta in img_metas:
img_meta.update(input_shape=input_shape)
if img.dim() == 5:
if img.size(0) == 1 and img.size(1) != 1:
img.squeeze_()
else:
B, N, C, H, W = img.size()
img = img.view(B * N, C, H, W) # 这里将维度降维到4维
if self.use_grid_mask:
img = self.grid_mask(img)
img_feats = self.img_backbone(img) # 送入backbone,输出的是BN,Cout,Hout,Wout维度,list里是设置输出的层数
if isinstance(img_feats, dict):
img_feats = list(img_feats.values())
else:
return None
if self.with_img_neck:
img_feats = self.img_neck(img_feats) # 送到FPN中提取多层特征
img_feats_reshaped = []
for img_feat in img_feats:
BN, C, H, W = img_feat.size()
img_feats_reshaped.append(img_feat.view(B, int(BN / B), C, H, W)) # 将每个特征图的维度重新包装成B,N,C,H,W
return img_feats_reshapedneck是FPN,不必多说。petr_head定义了decoder的结构,与DETR基本类似,主要不同就是PETR_head里面前向forward过程中的变化,这里先略过,先熟悉整体代码流程。
img_neck=dict(
type='CPFPN',
in_channels=[1024, 2048],
out_channels=256, # FPN输出256个通道
num_outs=2),
pts_bbox_head=dict(
type='PETRHead',
num_classes=10,
in_channels=256, # 输入通道数为256
num_query=900, # 设置了900个query初始化
LID=True,
with_position=True,
with_multiview=True,
position_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
normedlinear=False,
transformer=dict( # 使用的Transformer定义
type='PETRTransformer',
decoder=dict(
type='PETRTransformerDecoder',
return_intermediate=True,
num_layers=6,
transformerlayers=dict(
type='PETRTransformerDecoderLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.1),
dict(
type='PETRMultiheadAttention',
embed_dims=256,
num_heads=8,
dropout=0.1),
],
feedforward_channels=2048,
ffn_dropout=0.1,
with_cp=True,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')),
)),
bbox_coder=dict(
type='NMSFreeCoder',
# type='NMSFreeClsCoder',
post_center_range=[-61.2, -61.2, -10.0, 61.2, 61.2, 10.0],
pc_range=point_cloud_range,
max_num=300,
voxel_size=voxel_size,
num_classes=10),
positional_encoding=dict(
type='SinePositionalEncoding3D', num_feats=128, normalize=True),到这里模型的定义基本完成,具体petr_head的细节在后面解释。positional_encoding是DETR中的位置编码,不是PETR的positional_embedding,positional_embedding的定义是在petr_head.py当中作为一个函数加进去的,后面会说。
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=2.0),
loss_bbox=dict(type='L1Loss', loss_weight=0.25),
loss_iou=dict(type='GIoULoss', loss_weight=0.0)),
# model training and testing settings
train_cfg=dict(pts=dict(
grid_size=[512, 512, 1],
voxel_size=voxel_size,
point_cloud_range=point_cloud_range,
out_size_factor=4,
assigner=dict(
type='HungarianAssigner3D',
cls_cost=dict(type='FocalLossCost', weight=2.0),
reg_cost=dict(type='BBox3DL1Cost', weight=0.25),
iou_cost=dict(type='IoUCost', weight=0.0), # Fake cost. This is just to make it compatible with DETR head.
pc_range=point_cloud_range))))这里是损失函数的定义使用的都是mmdet中自带的损失定义,Focalloss作为分类损失,L1和GIoU作为回归损失,匈牙利损失为Transformer的分类匹配损失。
下面是训练流程的配置,这里以前没有搞明白是做什么的,其实这里才是数据加载的重要过程,数据集的最终load进内存后进行预处理的过程是在这个pipeline当中完成的,要想知道输入给模型的数据是什么格式,是什么样的组织结构需要对这个地方有了解。
train_pipeline = [
dict(type='LoadMultiViewImageFromFiles', to_float32=True),
dict(type='LoadAnnotations3D', with_bbox_3d=True, with_label_3d=True, with_attr_label=False),
dict(type='ObjectRangeFilter', point_cloud_range=point_cloud_range),
dict(type='ObjectNameFilter', classes=class_names),
dict(type='ResizeCropFlipImage', data_aug_conf = ida_aug_conf, training=True),
dict(type='GlobalRotScaleTransImage',
rot_range=[-0.3925, 0.3925],
translation_std=[0, 0, 0],
scale_ratio_range=[0.95, 1.05],
reverse_angle=True,
training=True
),
dict(type='NormalizeMultiviewImage', **img_norm_cfg),
dict(type='PadMultiViewImage', size_divisor=32),
dict(type='DefaultFormatBundle3D', class_names=class_names),
dict(type='Collect3D', keys=['gt_bboxes_3d', 'gt_labels_3d', 'img'])
]需要关注一下“LoadMultiViewImageFromFiles”这个过程
首先先来看一下数据集是如何定义的,在 nuscenes_dataset.py 中:
class CustomNuScenesDataset(NuScenesDataset):
...
def get_data_info(self, index):
...
if self.modality['use_camera']:
image_paths = []
for cam_type, cam_info in info['cams'].items():
img_timestamp.append(cam_info['timestamp'] / 1e6)
image_paths.append(cam_info['data_path'])
...
input_dict.update(
dict(
img_timestamp=img_timestamp,
img_filename=image_paths, # dict 前面的key:img_filename直接转化为“img_filename”:image_path字符串
lidar2img=lidar2img_rts,
intrinsics=intrinsics,
extrinsics=extrinsics
))
return input_dict可以看到输出的data信息只有图像的文件路径,并没有加载进内存。
在 loading.py中
class LoadMultiViewImageFromFiles(object):
def __call__(self, results):
"""Call function to load multi-view image from files.
Args:
results (dict): Result dict containing multi-view image filenames.
Returns:
dict: The result dict containing the multi-view image data. \
Added keys and values are described below.
- filename (str): Multi-view image filenames.
- img (np.ndarray): Multi-view image arrays.
- img_shape (tuple[int]): Shape of multi-view image arrays.
- ori_shape (tuple[int]): Shape of original image arrays.
- pad_shape (tuple[int]): Shape of padded image arrays.
- scale_factor (float): Scale factor.
- img_norm_cfg (dict): Normalization configuration of images.
"""
filename = results['img_filename']
# img is of shape (h, w, c, num_views)
# 这里根据数据集的输出,将图像地址找到加载起来,每一个img_filename内是一个时刻下6个相机的图像地址,将其堆叠起来
img = np.stack(
[mmcv.imread(name, self.color_type) for name in filename], axis=-1)
if self.to_float32:
img = img.astype(np.float32)
results['filename'] = filename
# unravel to list, see `DefaultFormatBundle` in formating.py
# which will transpose each image separately and then stack into array
results['img'] = [img[..., i] for i in range(img.shape[-1])]
# 转为列表形式,维数为 N,C,H,W。
results['img_shape'] = img.shape
results['ori_shape'] = img.shape
# Set initial values for default meta_keys
results['pad_shape'] = img.shape
results['scale_factor'] = 1.0
num_channels = 1 if len(img.shape) < 3 else img.shape[2]
results['img_norm_cfg'] = dict(
mean=np.zeros(num_channels, dtype=np.float32),
std=np.ones(num_channels, dtype=np.float32),
to_rgb=False)
return results这一部分看明白后,就可以知道送入\(\color{Red} {backbone}\)的数据为什么是(B,N,C,H,W)的维数了。backbone通过一次直接处理BN张(C,H,W)的图像数据,一次性的可以提取N个视角下的多目图像特征,在后续的encoder-decoder模块内可以学习到多个图像特征间的关联,实现特征融合。
最后的\(\color{Red} {Collect3D}\)步骤是将key内的元素提取出来。于是训练阶段的输入数据就包括了[‘gt_bboxes_3d’, ‘gt_labels_3d’, ‘img’]这三个内容。
数据集的配置部分,这里只是配置了数据集的一些基本情况,重点部分还是上面流水线与数据集的接口部分比较重要。
dataset_type = 'CustomNuScenesDataset'
data_root = './data/nuscenes/'
data = dict(
samples_per_gpu=4, # 这里是batch size,一般来说越大越好,我用的4090有24gb显存,只能开到4.
workers_per_gpu=4, # 多进程加载数据,这里用了4个进程。
train=dict(
type=dataset_type, # 数据集的定义
data_root=data_root, # 数据集的路径
ann_file=data_root + 'nuscenes_infos_train.pkl',
pipeline=train_pipeline,
classes=class_names,
modality=input_modality,
test_mode=False,
use_valid_flag=True,
# we use box_type_3d='LiDAR' in kitti and nuscenes dataset
# and box_type_3d='Depth' in sunrgbd and scannet dataset.
box_type_3d='LiDAR'),
val=dict(type=dataset_type, pipeline=test_pipeline, classes=class_names, modality=input_modality),
test=dict(type=dataset_type, pipeline=test_pipeline, classes=class_names, modality=input_modality))剩下的部分就比较容易理解了,配置优化器和学习率等等,属于不需要较多改动的部分。
optimizer = dict(
type='AdamW',
lr=2e-4,
paramwise_cfg=dict(
custom_keys={
'img_backbone': dict(lr_mult=0.1),
}),
weight_decay=0.01)
optimizer_config = dict(type='Fp16OptimizerHook', loss_scale=512., grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='CosineAnnealing',
warmup='linear',
warmup_iters=500,
warmup_ratio=1.0 / 3,
min_lr_ratio=1e-3,
# by_epoch=False
)
total_epochs = 24
evaluation = dict(interval=24, pipeline=test_pipeline)
find_unused_parameters = False
runner = dict(type='EpochBasedRunner', max_epochs=total_epochs)
load_from=None
resume_from='work_dirs/petr_r50dcn_gridmask_p4/latest.pth'PETR HEAD
我们先从最上层的PETR模型开始
petr.py
@DETECTORS.register_module()
class Petr3D(MVXTwoStageDetector):
...
def forward_train(...):
img_feats = self.extract_feat(img=img, img_metas=img_metas)
losses = dict()
losses_pts = self.forward_pts_train(img_feats, gt_bboxes_3d,
gt_labels_3d, img_metas,
gt_bboxes_ignore)
losses.update(losses_pts)
return losses
def forward_pts_train(...):
outs = self.pts_bbox_head(pts_feats, img_metas)
loss_inputs = [gt_bboxes_3d, gt_labels_3d, outs]
losses = self.pts_bbox_head.loss(*loss_inputs)
return losses通过 backbone 提取特征后送入petr_head得到输出,和真值计算损失后输出一个训练损失,即为一个训练。
petr_head.py 这个文件中就完成了PETR对于DETR的改进部分和自己的创新点。理解PETR文章即为理解这一部分代码。
@HEADS.register_module()
class PETRHead(AnchorFreeHead):
def forward(self, mlvl_feats, img_metas):
x = mlvl_feats[0] # 首先x为深层的特征图,即fpn输出的256维的tensor
batch_size, num_cams = x.size(0), x.size(1)
input_img_h, input_img_w, _ = img_metas[0]['pad_shape'][0]
masks = x.new_ones(
(batch_size, num_cams, input_img_h, input_img_w)) # 新生成与原始输入大小相同的mask
for img_id in range(batch_size):
for cam_id in range(num_cams):
img_h, img_w, _ = img_metas[img_id]['img_shape'][cam_id]
masks[img_id, cam_id, :img_h, :img_w] = 0
# 图像像素对齐操作
x = self.input_proj(x.flatten(0,1)) # self.input_proj = Conv2d(self.in_channels, self.embed_dims, kernel_size=1) 先经过一层卷积降维 self.embed_dims = 256
x = x.view(batch_size, num_cams, *x.shape[-3:]) # BNCHW
# interpolate masks to have the same spatial shape with x
masks = F.interpolate(
masks, size=x.shape[-2:]).to(torch.bool)
if self.with_position:
coords_position_embeding, _ = self.position_embeding(mlvl_feats, img_metas, masks) # 这里是PE的部分,PE的具体原理在下一部分说明
pos_embed = coords_position_embeding
if self.with_multiview:
sin_embed = self.positional_encoding(masks) # DETR的positional encoding,作用是图像的位置编码
sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())
pos_embed = pos_embed + sin_embed # 两部分相加作为transformer的positional encoding
# self.adapt_pos3d = nn.Sequential(
# nn.Conv2d(self.embed_dims*3//2, self.embed_dims*4, kernel_size=1, stride=1, padding=0),
# nn.ReLU(),
# nn.Conv2d(self.embed_dims*4, self.embed_dims, kernel_size=1, stride=1, padding=0),
# )
else:
pos_embeds = []
for i in range(num_cams):
xy_embed = self.positional_encoding(masks[:, i, :, :])
pos_embeds.append(xy_embed.unsqueeze(1))
sin_embed = torch.cat(pos_embeds, 1)
sin_embed = self.adapt_pos3d(sin_embed.flatten(0, 1)).view(x.size())
pos_embed = pos_embed + sin_embed
else:
if self.with_multiview:
pos_embed = self.positional_encoding(masks)
pos_embed = self.adapt_pos3d(pos_embed.flatten(0, 1)).view(x.size())
else:
pos_embeds = []
for i in range(num_cams):
pos_embed = self.positional_encoding(masks[:, i, :, :])
pos_embeds.append(pos_embed.unsqueeze(1))
pos_embed = torch.cat(pos_embeds, 1)
reference_points = self.reference_points.weight # shape(num_query,3) 应该是每个query初始化一个point 这里的num_query=100
# self.reference_points = nn.Embedding(self.num_query, 3) 使用了里面的可学习参数作为querry,因此querry是通过学习不断改变的
query_embeds = self.query_embedding(pos2posemb3d(reference_points)) # querry后续操作
# self.query_embedding = nn.Sequential(
# nn.Linear(self.embed_dims*3//2, self.embed_dims),
# nn.ReLU(),
# nn.Linear(self.embed_dims, self.embed_dims),
# )
reference_points = reference_points.unsqueeze(0).repeat(batch_size, 1, 1) #.sigmoid()
outs_dec, _ = self.transformer(x, masks, query_embeds, pos_embed, self.reg_branches) # transformer操作
outs_dec = torch.nan_to_num(outs_dec)
outputs_classes = []
outputs_coords = []
# outs_dec 输出的每一项表示一个视角的检测目标。这里的操作是将深度信息与之前的坐标系对齐(即加上参考点的位置)
for lvl in range(outs_dec.shape[0]):
reference = inverse_sigmoid(reference_points.clone())
assert reference.shape[-1] == 3
outputs_class = self.cls_branches[lvl](outs_dec[lvl])
tmp = self.reg_branches[lvl](outs_dec[lvl])
# 因为输出的格式是(cx, cy, w, l, cz, h, theta, vx, vy)
# 将输出的偏移量相加后再归一化,即网络计算的是位置的偏移量
tmp[..., 0:2] += reference[..., 0:2]
tmp[..., 0:2] = tmp[..., 0:2].sigmoid()
tmp[..., 4:5] += reference[..., 2:3] # 因为reference是(num_querry,3) 第三维是z,所以这里是2:3
tmp[..., 4:5] = tmp[..., 4:5].sigmoid()
outputs_coord = tmp
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
all_cls_scores = torch.stack(outputs_classes)
all_bbox_preds = torch.stack(outputs_coords)
# 筛选出处于检测范围内的目标
all_bbox_preds[..., 0:1] = (all_bbox_preds[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0])
all_bbox_preds[..., 1:2] = (all_bbox_preds[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1])
all_bbox_preds[..., 4:5] = (all_bbox_preds[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2])
outs = {
'all_cls_scores': all_cls_scores,
'all_bbox_preds': all_bbox_preds,
'enc_cls_scores': None,
'enc_bbox_preds': None,
}
return outs这里输出了所有检测到的目标。 position_embedding部分
def position_embeding(self, img_feats, img_metas, masks=None):
eps = 1e-5
pad_h, pad_w, _ = img_metas[0]['pad_shape'][0]
B, N, C, H, W = img_feats[self.position_level].shape
coords_h = torch.arange(H, device=img_feats[0].device).float() * pad_h / H # 生成像素平面内的网格
coords_w = torch.arange(W, device=img_feats[0].device).float() * pad_w / W
if self.LID: # 线性分划网络
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float() # 深度范围内的网格
index_1 = index + 1
bin_size = (self.position_range[3] - self.depth_start) / (self.depth_num * (1 + self.depth_num))
coords_d = self.depth_start + bin_size * index * index_1
else:
index = torch.arange(start=0, end=self.depth_num, step=1, device=img_feats[0].device).float()
bin_size = (self.position_range[3] - self.depth_start) / self.depth_num
coords_d = self.depth_start + bin_size * index
D = coords_d.shape[0]
coords = torch.stack(torch.meshgrid([coords_w, coords_h, coords_d])).permute(1, 2, 3, 0) # W, H, D, 3 # meshgrid就是生成体素网格
coords = torch.cat((coords, torch.ones_like(coords[..., :1])), -1) #增加一维,与内参矩阵对应
coords[..., :2] = coords[..., :2] * torch.maximum(coords[..., 2:3], torch.ones_like(coords[..., 2:3])*eps)
img2lidars = []
for img_meta in img_metas:
img2lidar = []
for i in range(len(img_meta['lidar2img'])):
img2lidar.append(np.linalg.inv(img_meta['lidar2img'][i])) #乘内参矩阵的逆将相机坐标系转换到世界坐标系
img2lidars.append(np.asarray(img2lidar))
img2lidars = np.asarray(img2lidars)
img2lidars = coords.new_tensor(img2lidars) # (B, N, 4, 4)
coords = coords.view(1, 1, W, H, D, 4, 1).repeat(B, N, 1, 1, 1, 1, 1)
img2lidars = img2lidars.view(B, N, 1, 1, 1, 4, 4).repeat(1, 1, W, H, D, 1, 1)
coords3d = torch.matmul(img2lidars, coords).squeeze(-1)[..., :3] # 划定范围
coords3d[..., 0:1] = (coords3d[..., 0:1] - self.position_range[0]) / (self.position_range[3] - self.position_range[0])
coords3d[..., 1:2] = (coords3d[..., 1:2] - self.position_range[1]) / (self.position_range[4] - self.position_range[1])
coords3d[..., 2:3] = (coords3d[..., 2:3] - self.position_range[2]) / (self.position_range[5] - self.position_range[2])
coords_mask = (coords3d > 1.0) | (coords3d < 0.0) # 不在范围内的元素将被mask遮住
coords_mask = coords_mask.flatten(-2).sum(-1) > (D * 0.5)
coords_mask = masks | coords_mask.permute(0, 1, 3, 2)
coords3d = coords3d.permute(0, 1, 4, 5, 3, 2).contiguous().view(B*N, -1, H, W)
coords3d = inverse_sigmoid(coords3d) # 归一化
coords_position_embeding = self.position_encoder(coords3d) # 送入几层卷积网络中,进一步加深编码信息
return coords_position_embeding.view(B, N, self.embed_dims, H, W), coords_mask