
MMD3D模型训练测试群流程解析
MMD3D模型训练测试全流程解析
[TOC]
训练与验证流程
在训练开始之前,我们需要编写配置文件。MMClassification 在
configs
文件夹中提供了各种模型常用的样例配置文件,可以直接使用或是稍作修改以用于自己的任务。
完成配置文件的编写之后,我们就可以使用入口脚本
tools/train.py
进行训练和验证。该脚本会进行数据集、模型相关的初始化,并调用高阶 API
train_model
来搭建执行器(Runner),模型的训练和验证步骤均由执行器进行调度。
更完整的配置文件教程可见:https://mmclassification.readthedocs.io/zh_CN/latest/tutorials/config.html
这里我们仅以 MMClassification 为基准,介绍从训练入口开始,我们是如何让模型训练起来的,避免大家在 OpenMMLab 架构中迷路,那么让我们出发~
第一站 tools/train.py
正如上文所说,这里是训练和验证的入口脚本。它主要执行的工作是解析命令行参数、环境信息,把这些信息动态更新到配置文件中,做一些诸如打印环境信息、创建工作目录之类的外围操作。除此之外,它还完成了模型和训练数据集的构建。
之后调用高阶 API——train_model 继续我们的训练任务:
def main():
# 读取命令行参数
args = parse_args()
# 读取配置文件
cfg = Config.fromfile(args.config)
# 合并 `--cfg-options` 至配置文件
if args.cfg_options is not None:
cfg.merge_from_dict(args.cfg_options)
# 收集并配置运行设备、工作目录、随机种子等信息
...
# 构建模型并初始化权重
model = build_classifier(cfg.model)
model.init_weights()
# 构建数据集
datasets = [build_dataset(cfg.data.train)]
...
# 调用高阶 API train_model 进行模型训练
train_model(
model,
datasets,
cfg,
distributed=distributed,
validate=(not args.no_validate),
timestamp=timestamp,
device=args.device,
meta=meta)第二站 train_model
该函数的主要任务是搭建并执行训练执行器,这里我们通过一份流程图来了解它所做的工作:
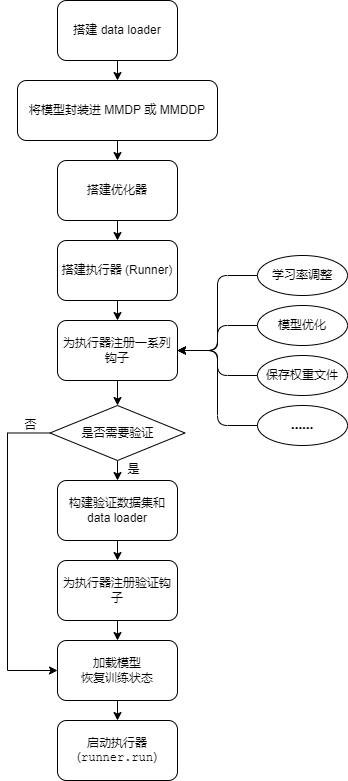
在函数的最后,我们使用 runner.run
启动了执行器,由执行器来进行具体的训练。需要额外注意的是:模型的验证并没有使用相同的方式,而是作为执行器的一个钩子,利用
Hook 技术实现模型的验证。
第三站runner.run
从这里开始,程序代码转入了 MMCV,许多小伙伴在查阅源码时就会有些困惑,不知道接下来该去哪里跟踪源码,执行器到底调用了模型的哪个接口呢?我想要 debug 该去哪里加断点呢?其实这里并不复杂,让我们一步一步跟踪执行器。
这里我们以分类任务最常用的 EpochBasedRunner
为例进行说明。
以下提到的 runner 也均指
EpochBasedRunner
相关代码可以在 https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/epoch_based_runner.py 中找到
如下图所示,runner.run 方法会逐 epoch 地去调用
runner.train 方法,而 runner.train 又会逐
iteration 地去调用 runner.run_iter 方法。

很多人在翻阅执行器源码时会被 run
方法较为复杂的逻辑搞乱,其实其中核心的语句为如下几行:
def run(self, data_loaders, workflow, max_epochs=None, **kwargs):
...
while self.epoch < self._max_epochs:
for i, flow in enumerate(workflow):
mode, epochs = flow
if isinstance(mode, str): # self.train()
if not hasattr(self, mode):
raise ValueError(
f'runner has no method named "{mode}" to run an '
'epoch')
epoch_runner = getattr(self, mode)
else:
raise TypeError(
'mode in workflow must be a str, but got {}'.format(
type(mode)))
for _ in range(epochs):
if mode == 'train' and self.epoch >= self._max_epochs:
break
epoch_runner(data_loaders[i], **kwargs)那么,代码在哪里调用了 runner.train
方法?这还要追溯到我们的配置文件中,在默认的配置文件中都会有这么一行:
workflow = [('train', 1)]其中第一个元素是 'train' ,对应着代码中的
mode,代码中使用 getattr(self, mode)
的方式取出了执行器的 train 方法。至于相关的 workflow
设计,感兴趣的小伙伴可以看一下 MMCV 核心组件分析(七):
Runner,这里我们就不多做介绍,通常也不推荐大家在没有特殊需求的情况下,在分类任务中修改
workflow。
总之,我们终于接近了终点,要从执行器中跳回 MMClassification 了。在
runner.run_iter 中,执行器调用了模型的
train_step 方法如下:
outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)第四站 model.train_step
首先一个问题是,执行器中的 self.model
是哪个类?严谨地说,通常情况下它是 MMDataParallel(MMDP)
或者 MMDistributedDataParallel(MMDDP),因为
train_model
函数对模型进行了封装。但这对于我们理解训练流程并不重要,因为 MMDP 或者
MMDDP 只是一层封装,它们还是会调用所封装模型的 train_step
方法。
那么这个被封装的模型是哪个类呢?其实很简单,在配置文件中,我们的
model 字段通常定义如下,其中
type='ImageClassifier',因此我们主模型是
ImageClassifier 类。
model = dict(
type='ImageClassifier',
backbone=...,
neck=...,
head=...,
))通常,主模型和算法本身的架构相关。如检测任务中,根据算法的不同,主模型可以是
RetinaNet、YOLOX
这样的算法。但在分类任务中,由于 MMClassification
目前还仅支持单标签和多标签的监督学习,这些算法基本都遵循着
“主干网络+可选的 GAP +分类头” 的总体结构,因而我们只有
ImageClassifier 这么一个主模型,期待将来 MMClassficiation
支持更多的任务吧~
在进入 ImageClassfier.``train_step(该方法定义在基类
BaseClassifier 中) 之后,我们发现,train_step
依然是一个“中间商”,它调用了模型的 forward 方法,并指定
return_loss=True,进而调用模型的 forward_train
方法。
def train_step(self, data, optimizer=None, **kwargs):
"""mmcls/models/classifiers/base.py"""
losses = self(**data) # --> forward
loss, log_vars = self._parse_losses(losses)
outputs = dict(
loss=loss, log_vars=log_vars, num_samples=len(data['img'].data))
return outputs
def forward(self, img, return_loss=True, **kwargs):
"""mmcls/models/classifiers/base.py"""
if return_loss:
return self.forward_train(img, **kwargs)
else:
return self.forward_test(img, **kwargs)
def forward_train(self, img, gt_label, **kwargs):
"""mmcls/models/classifiers/image.py"""
if self.augments is not None:
img, gt_label = self.augments(img, gt_label)
# 调用 backbone 和 neck 的 forward
x = self.extract_feat(img)
losses = dict()
# 在 head 中计算 loss
loss = self.head.forward_train(x, gt_label)
losses.update(loss)
return losses是否有些混乱了?其实简单来说,因为我们将损失函数定义在了分类头中,在训练时我们希望分类头返回损失函数,在验证或测试时我们希望分类头返回各类得分,因此通过
forward 方法和 return_loss
参数来做中间的分发,实际在训练中走的是模型的 forward_train
方法,在这里,数据终于历尽千辛万苦,进入了主干网络、分类头等模型结构中。
测试流程
相较于训练流程,模型的测试流程就简单很多了。这里没有再使用执行器,而是直接在高级
API single_gpu_test 或是 multi_gpu_test
中调用模型进行测试。具体流程如下:
- 在入口脚本
tools/test.py中,我们完成了命令参数的解析、数据集及 data loader 的构建、模型的构建及封装,并调用**single_gpu_test**或是**multi_gpu_test**获取测试结果。 - 在
single_gpu_test或是multi_gpu_test中,我们遍历整个 data loader 中的数据,调用模型的forward方法,并传入参数return_loss=False。在上一节中我们已经提到了,模型的forward方法会根据return_loss参数执行模型的不同分支,当return_loss=False时,会调用模型的**forward_test**函数,去获得模型预测结果,而不是损失函数。 forward_test函数的源码如下。虽然目前 MMClassification 还不支持 TTA(Test-Time Augmentation),但为了保持 OpenMMLab 各算法库风格统一,这里对输入参数imgs做了许多额外的判断。在目前 MMClassification 的测试流程中,imgs参数只会是一个 batch 的图像,即一个形状为(N, C, H, W)的 Tensor。因此目前我们可以简单地认为**forward_test**进一步调用了模型的**simple_test**方法。
def forward_test(self, imgs, **kwargs):
"""
Args:
imgs (Tensor | List[Tensor]): the outer list indicates test-time
augmentations and inner Tensor should have a shape NxCxHxW,
which contains all images in the batch.
"""
if isinstance(imgs, torch.Tensor):
imgs = [imgs]
for var, name in [(imgs, 'imgs')]:
if not isinstance(var, list):
raise TypeError(f'{name} must be a list, but got {type(var)}')
if len(imgs) == 1:
return self.simple_test(imgs[0], **kwargs)
else:
raise NotImplementedError('aug_test has not been implemented')终于,我们获得模型在整个数据集中的推理结果,返回到了
tools/test.py 中。之后,我们会调用数据集的
**evalutate**
方法,将数据集的推理结果传递进去,由
evaluate 方法来处理各种评价指标的计算